Experiment Decision Framework
ProDecision Framework is available on Pro and Enterprise plans.
The Experiment Decision Framework (EDF) is a set of tools and customizable settings to help streamline and improve experiment decision making. The EDF can help answer questions like, "Should I keep running my experiment?" and "Do my results meet my success criteria?"
The EDF has two key components:
- The Decision Criteria
- The Target Minimum Detectable Effects (MDEs) for your goal metrics
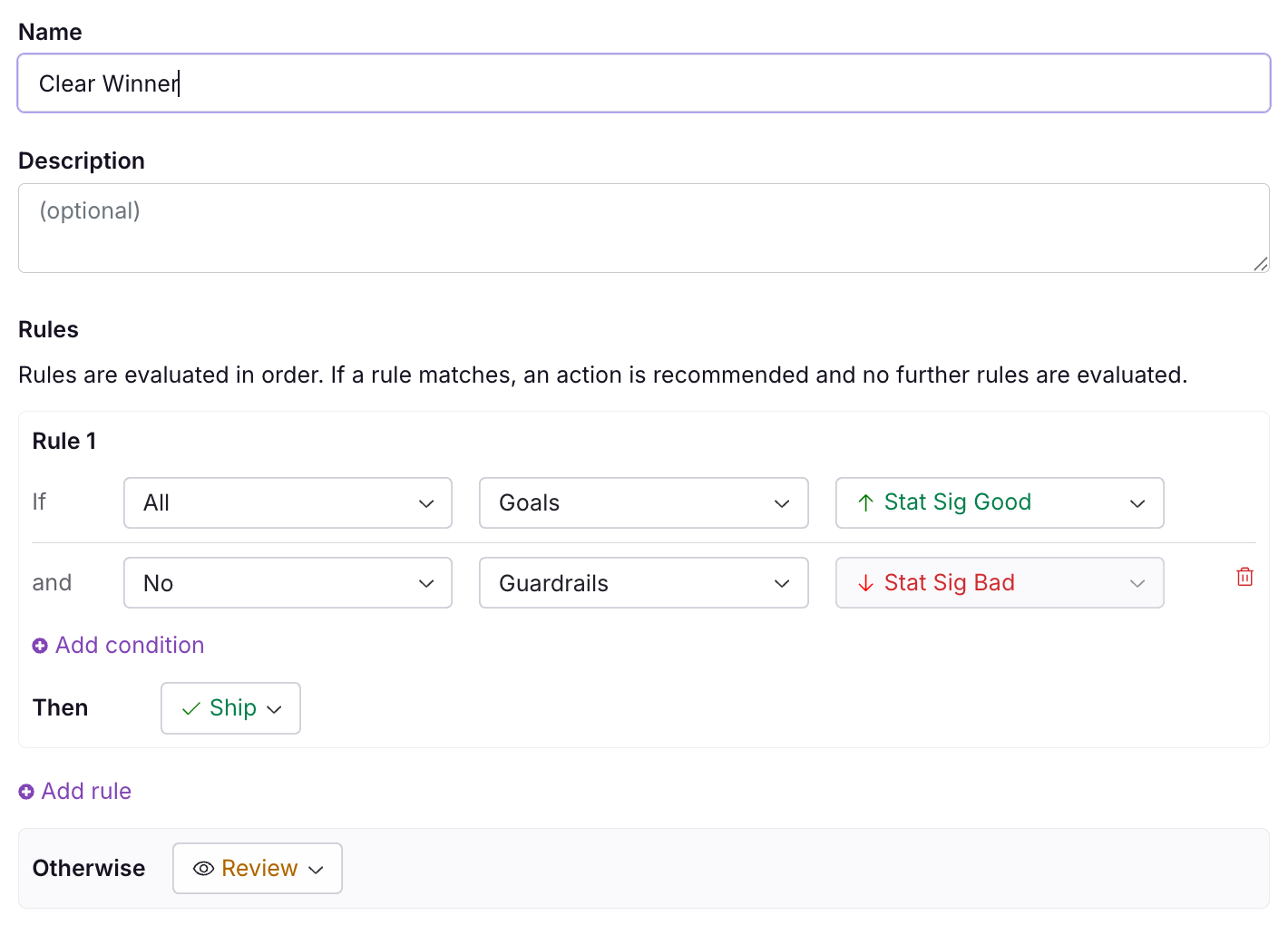
Decision Criteria
The Decision Criteria are the ways that your results in an experiment lead to a decision. Do all goal metrics need to be statistically significant and positive to ship, or are you happy to ship so long as none are statistically significant and negative? These can be customized or you can use our two out-of-the-box options: (1) Clear Signals, which requires no guardrail failures and all goal metric successes, or (2) Do No Harm, which only requires that no metrics are statistically significant in the harmful direction.
Target Minimum Detectable Effects
The Target Minimum Detectable Effects (MDEs) are the smallest effects you want to be able to reliably detect before making a decision. For example, suppose 10% is your target MDE value (10% is the GrowthBook default). If your confidence intervals range from 10 to 20%, then you have reached your desired precision. Once this desired precision is reached, your experiment has collected enough data for the decision criteria to be applied and a ship, rollback, or review decision is given for your experiment. Note: sometimes a decision is given before the target MDE is reached if either (1) results are significant at a very strict threshold or (2) if you have sequential testing enabled.
Once an experiment has reached the needed precision, we make a recommendation based on the Decision Criteria for your experiment.

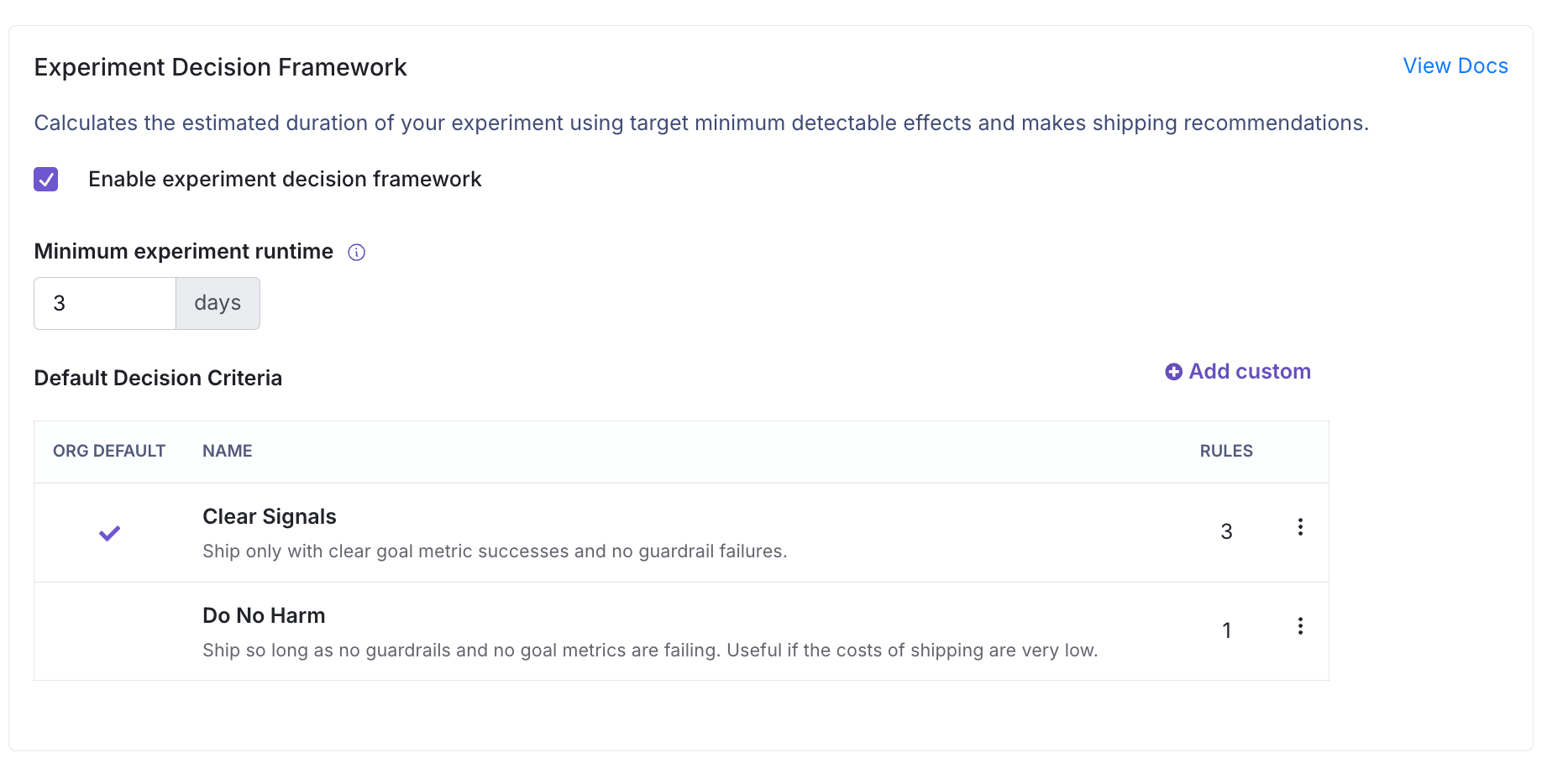
Setting up the Experiment Decision Framework
You can set up the Experiment Decision Framework under Settings > General > Experiment Settings.
- Under
Settings > General > Experiment Settings, set theMinimum experiment runtime, which stops the decision framework from displaying days remaining or experiment decisions while early data collection is ongoing. The default value is 3 days, but larger values such as 7 may be reasonable, especially if there are strong day of the week effects in your data. - Set the
Target Minimum Detectable Effects(target MDEs) for your key goal metrics. You can set the default for all metrics on theSettings > General > Metric & Datatab. The GrowthBook default is 10%, with selection guidance below. - Create the
Decision Criteriathat you want your experiments to follow underSettings > General > Experiment Settings. - Review your Experiment creation process! The EDF relies heavily upon using your Goal Metrics to determine how long your experiment needs to run as well as what decision to make. If you have 3 or more goal metrics, or even 2 competing goal metrics, it can take a lot longer for your experiment to finish and reach a clear shipping recommendation. Consider setting only one goal metric, and use secondary metrics to deep dive your results and build more understanding.
Customizing the decision framework per experiment
The above process lets you select defaults for your Organization, but the decision framework can also be customized per experiment.
On the Experiment Overview Tab, under Analysis Settings, you can customize the target MDEs for the goal metrics in your experiment or change the decision criteria to apply to the experiment.
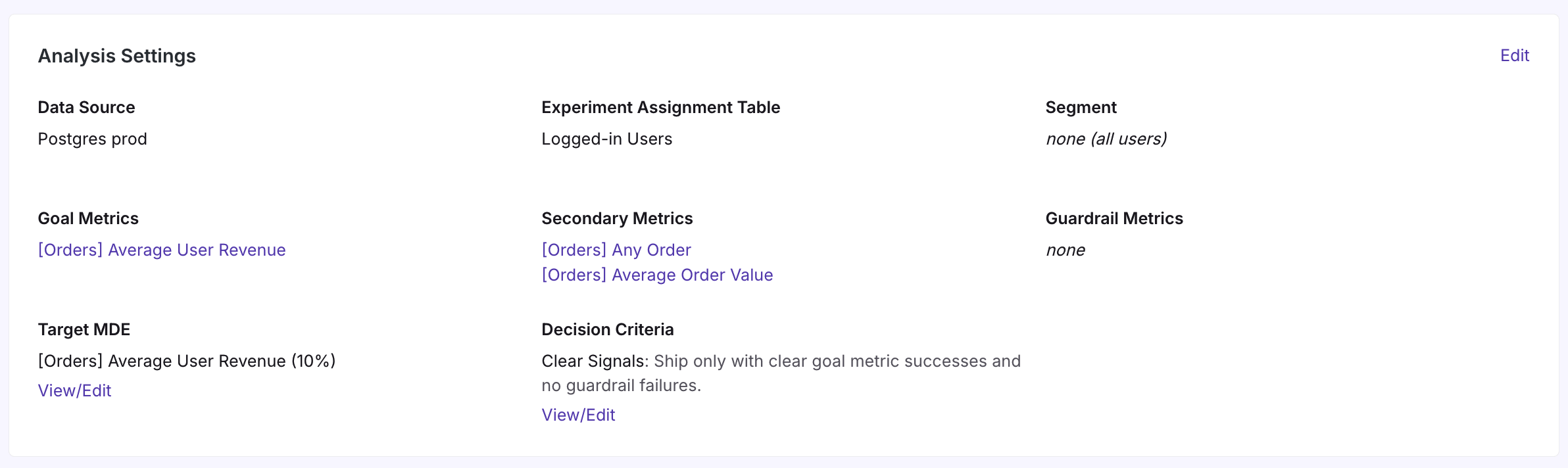
Selecting Target Minimum Detectable Effects
The target MDE is the smallest effect you want to be able to reliably detect before making a decision. For example, suppose 10% is your target MDE value (10% is the GrowthBook default). If your confidence intervals range from 0 to 20%, then a 10% lift would be statistically significant, your target MDE has been reached, and your experiment is ready for decision.
Please note that the time at which you reach your target MDE is unaffected by the lift estimate in your experiment. In the above example, only the inputted target MDE and the width of your confidence interval are used to determine if you have reached your target MDE. If your estimated lift in your experiment was 5%, but your confidence interval ranged from -5% to 15%, your results would not be statistically significant even though you reached your target MDE. That means you're comfortable making a ship or roll back decision with this amount of power, even if your results are not statistically significant. If your estimated lift was 20% with the same interval width, then your results would be statistically significant, and you should ship. The target MDE helps ensure that the experiments you run are well-powered, not that results from an individual experiment will be statistically significant.
Your target MDE should balance the lift at which it is profitable to ship against the time needed to run the experiment. Small target MDEs will let you detect tinier effects before being ready to make a decision, but they will require more data. Large target MDEs will shorten experiment runtimes, but if your true effects are smaller than your target MDEs, you will often face ambiguity at the end of your experiment.
Experiment Statuses
Experiments have a variety of statuses represented as badges on the Experiment Detail page and in the Experiment List based on whether they are in Draft, Running, or are Stopped. For Stopped experiments, your stated reason for calling the experiment is included in the status.
For running experiments, there are a variety of statuses, each depending on the current state of your experiment and your settings. Many statuses have an associated tooltip that explains them in more detail.
Note: only unhealthy and no data statuses appear before your experiment has been running for your organization's minimum experiment duration, which defaults to 3 days.
| Status | Status conditions | What to do next |
|---|---|---|
| Unhealthy | This status appears when your experiment results has imbalanced traffic (SRM), multiple exposures, or is low-powered. | For SRM or multiple exposures, see the troubleshooting doc. For low-powered experiments, see the FAQ below. |
| No data | This status appears when your experiment results have refreshed, but there are no users showing up in your experiment. | You have no traffic or are missing some datasource and metric configurations. There are three common causes if you have no traffic: (1) you just started your experiment and you just need to wait for your experiment exposure data to land in your data warehouse before it will show up in GrowthBook; (2) you started your experiment but there are no linked feature flags, visual editor changes, or URL redirects attached (see the Experiment Overview > Implementation section) that are actually exposing users to your experiment and getting traffic; (3) you have some issue configuring your Experiment Assignment Query or something else in your GrowthBook set-up that is likely affecting multiple experiments (more information here). |
| ~X days left | This status appears when your experiment has not yet reached the target power and it estimates how much longer you need to run the experiment to reach that target. | Continue to collect data until your target power is reached, or the experiment has been running longer than is feasible for your business goals. If the estimated duration is quite high, it is likely you have: (1) too many goal metrics, (2) your target minimum detectable effect (MDE) for your goal metrics is too small for your traffic, or (3) you are not getting very much new traffic in the experiment. We recommend selecting only 1 or 2 goal metrics and consider establishing more realistic target MDEs for your key goal metrics. |
| Ship now | This status appears when your decision criteria to Ship Now have been met for at least one variation AND either (1) Sequential Testing is enabled in our Frequentist engine OR (2) the goal metrics have reached their target MDEs (3) OR the effects are statistically significant at a strict threshold (Frequentist engine: p-value < 0.001; Bayesian engine: CTW > 99.9%). | Ship the variation that fits the above criteria! |
| Roll back now | This status appears when your decision criteria to Rollback Now have been met for all test variations AND either (1) Sequential Testing is enabled in our Frequentist engine OR (2) the goal metrics have reached their target MDEs (3) OR the effects are statistically significant at a strict threshold (Frequentist engine: p-value < 0.001; Bayesian engine: CTW > 99.9%) | Stop the experiment and keep the status quo! |
| Ready for review | This status appears when your decision criteria to Review have been met for any variation AND either (1) Sequential Testing is enabled in our Frequentist engine OR (2) the goal metrics have reached their target MDEs (3) OR the effects are statistically significant at a strict threshold (Frequentist engine: p-value < 0.001; Bayesian engine: CTW > 99.9%) cases. | Consider the trade-offs between shipping, rolling back and iterating, or continuing to run the experiment in these ambiguous cases. |
FAQ
What is target power?
Your experiment reaches its "target power" when it has enough data to reliably detect the target minimum detectable effect for all of your goal metrics. More data will help get more precise results, but based on the level of precision you want for your goal metrics, you have enough data to make a decision.
What should I do if my experiment has many days remaining or low power?
In these cases, the experiment traffic is not high enough to reliably detect the target MDE you have set for all of your goal metrics. This can often happen when:
- Your target MDE is too low for your traffic and metric - if you run low traffic experiments, or if you have a conversion metric that is very rare (e.g. less than 1%), then it can take a lot of data to precisely estimate effects. It is possible your target MDE for your metric is too low. Consider evaluating whether you are comfortable making decisions with more uncertainty, and consider increasing your target MDE in the settings for that metric.
- You have too many goal metrics - ideally you only have one or two goal metrics that decide whether or not you will launch an experiment variation. Picking a small number of goal metrics makes it easier to get enough power to make a decision. It forces you to clearly state up front your goals for your experiment, which makes decision making more straightforward. Finally, it can protect you from making up business goals to fit your results, rather than making sure your results fit your business goals.
- You have too many variations - having more variations splits your traffic and lowers the power you have to detect effects.