FAQ
Below are some frequently asked questions about GrowthBook.
Experiment Assignment
Do users always get assigned the same experiment variation?
GrowthBook SDKs use deterministic hashing to ensure the same user always gets assigned the same variation in an experiment.
In a nutshell, GrowthBook hashes together the hashAttribute (the user attribute used to assign a variation, ex: user id) and the experiment seed which produces a decimal between 0 and 1. Each variation is assigned a range of values (e.g. 0 to 0.5 and 0.5 to 1.0) and the user is assigned to whichever one their hash falls into.
This does mean, if you change the experiment configuration, some users may switch their assigned variation. For example, if someone has the hash 0.49 and you adjust the weights to a 40/60 experiment, the variation ranges become 0 to 0.4 and 0.4 to 1.0. In this case, the user was previously in the control group, but will now be in the variation.
GrowthBook will detect issues like this and will remove users who see both variations from the analysis automatically. However, to keep things simple and safe, we recommend not relying on this and treating experiments as immutable once they are running.
It's important to note that the above only applies when changing the traffic split between variations. If you keep the split the same, but increase the percent of traffic included, users will not switch variations. For example, if you are running a 50/50 experiment on 20% of traffic, the variation ranges will be 0 to 0.1 and 0.5 to 0.6. Users outside those ranges will be excluded from the experiment. If you increase the percent of traffic to 40%, but keep the 50/50 split, the ranges will become: 0 to 0.2 and 0.5 to 0.7. As you can see, no users switch variations. Instead, some users who were previously excluded are now part of the experiment.
What do I use for an "id" attribute in the SDK if my users aren't logged in?
If your application has both logged-in and anonymous users, we recommend using two identifier attributes:
idwhich is the database identifier of logged-in users (or empty string for anonymous)deviceId(orsessionId, etc.) which is a random anonymous hash, persisted in a cookie or local storage. This should always be set for both anonymous and logged-in users.
If your application only has anonymous users (e.g. a static marketing site), then we recommend a single id attribute which, similar to deviceId or sessionId above, is a random hash persisted in a cookie or local storage.
Running Experiments
How do I run an A/B test in GrowthBook?
The recommended way to run an A/B test is by using Feature Flags and our SDKs.
- Create a feature in GrowthBook (e.g.
new-signup-form) with an A/B Experiment rule - Use our SDKs to serve the different variations
if (growthbook.feature("new-signup-form").on) {
// Variation
} else {
// Control
}
What is the best way to redirect users to a URL based on their experiment variation?
You can now easily set up URL Redirect experiments within GrowthBook and customize navigation depending on your application. Read more about running a URL Redirect experiment here.
How much traffic do I need to run A/B tests?
What matters most for A/B testing is not traffic, but conversions. The general rule of thumb is to have at least 100-200 conversions per variation before you might start reaching significance.
So that means if you do 50 orders per week and that's the metric you are trying to optimize, you'll need to run a simple 2-way A/B test for at least 4-8 weeks. If you run a 3-way test, it will take 6-12 weeks.
Can I run multiple A/B tests at a time?
Yes! In fact, we recommend running many experiments in parallel in your application. Most A/B tests fail, so the more shots-on-goal you take, the more likely you are to get a winner. Running tests in parallel is a great way to increase your velocity.
Now it's possible your experiments might have interaction effects, but these are actually pretty rare in practice. One example is if one test is changing the text color on a page and another test is changing the background color. Some users might end up seeing black text on a black background, which is obviously not ideal. For these rare cases, you can use Namespaces to run mutually exclusive experiments. Make sure all experiments within the same Namespace are using the same hash attribute (assignment attribute).
As long as you apply a little common sense to avoid situations like the above, running multiple experiments has low risk and really high reward.
How does GrowthBook handle event data?
Check out the video below for a quick overview of how GrowthBook handles event data and how to fix common issues.
GrowthBook Cloud
What are the GrowthBook Cloud CDN usage limits?
GrowthBook Cloud CDN has limits that depend on your plan. New free accounts can make up to 1 million CDN requests per month and consume up to 5GB of bandwidth. New Pro accounts include 2 million CDN requests and 20GB of bandwidth, and can pay for additional usage above this. Enterprise accounts have custom limits and volume discounts.
For early adopters that joined GrowthBook Cloud before these new limits were introduced (March 2025), you will be grandfathered into the old limits of 10 million CDN requests and unlimited bandwidth per month. Thank you for being an early supporter!
You can view your current usage at any time in the GrowthBook Cloud dashboard under Settings > Usage.
How can I reduce my GrowthBook Cloud CDN usage?
There are a few ways to reduce your GrowthBook Cloud CDN usage:
- SDK Caching - Most of our SDKs support caching CDN responses. For back-end SDKs, this can drastically reduce the number of CDN requests since the response can be shared between many users. For front-end SDKs, caching has a smaller benefit, but can still help by eliminating duplicate requests from the same user.
- Nested CDNs - You can add your own custom CDN in front of our GrowthBook Cloud CDN. This will heavily decrease the number of requests that reach our CDN, but you will have to maintain this new infrastructure and pay for it outside of GrowthBook, so it might not end up reducing costs.
- GrowthBook Proxy - You can run self-hosted GrowthBook Proxy servers that cache CDN responses in your infrastructure. Like with nested CDNs, you will be responsible for maintaining and paying for this infrastructure.
What happens if I exceed the limits on GrowthBook Cloud?
We reserve the right to throttle or block CDN requests for accounts that exceed their free usage limits. We will always try to reach out to you before taking any action, but we reserve the right to take immediate action if we believe your usage is causing harm to other customers or our infrastructure.
For Pro and Enterprise customers, we will work with you to find a solution that meets your needs. This could include increasing your limits, optimizing your usage, or moving to a custom plan.
Self-Hosting
Which docker image tag should I use when self-hosting?
We recommend using the latest tag for both dev and production self-hosted deployments. This tag represents the latest stable build of GrowthBook and is what the Cloud app uses.
Specific version tags (e.g. v1.1.0) are only released periodically (about once a month) and you will miss out on the many bug fixes and features added between major releases.
We also recommend updating the image regularly. You can do that by downloading the latest image (docker pull growthbook/growthbook:latest) and restarting the container.
What are the hardware requirements for self-hosting GrowthBook?
The GrowthBook application is very lightweight and efficient. For most usecases, 2GB of memory is sufficient even for large production deployments.
GrowthBook only deals with aggregate data and the bulk of the processing is offloaded to your data source. Because of this, you can easily analyze terrabytes of data from your laptop or a small container in the cloud.
If you are using feature flags, we strongly recommend adding a caching layer between the GrowthBook API and your application in production. This will also help you stay within the limits of our Fair Use Policy. Some of our code examples implement caching. We offer a pre-built GrowthBook Proxy server you can run that handles caching and invalidation automatically. You can also setup your own CDN or distributed cache like Redis.
I can't upload to S3/getting 400 error when uploading to S3?
- Make sure you've correctly set the
S3_BUCKETandS3_REGIONenvironment variables - Enable bucket ACL and set ownership to Bucket owner preferred: read more here.
- Make sure the S3 bucket is publically accessible
- Make sure CORS settings are correct. Add your URLs to the AllowedOrigins array or set to "*"
Debugging the SDKs
Why is the trackingCallback not firing in the SDK?
The trackingCallback only fires when a user is included in an experiment. If you're expecting to be included and you're still not seeing the callback fire, it's likely for one of the following reasons:
- You are missing the
hashAttributefor the experiment. For example, when you are splitting users by "company", but the company attribute is empty. - The feature is disabled for the environment you are in (dev/prod)
- The experiment has reduced coverage. For example, if it's only running for 10% of users and you are in the 90% that are excluded.
- There is another feature rule that is taking precedence over the experiment.
If you are using the JavaScript or React SDK in a browser environment, you can install the GrowthBook DevTools Browser Extension for Chrome or Firefox to help you debug.
Note: To use the plugin, you will need to pass enableDevMode: true when creating your GrowthBook instance.
const growthbook = new GrowthBook({
enableDevMode: true,
})
How do I use the DevTools browser extension?
- Make sure you are using the React or JavaScript SDK
- Install the Chrome or Firefox DevTools Browser Extension
- Pass the
enableDevMode: trueoption into the GrowthBook constructor
const growthbook = new GrowthBook({
enableDevMode: true,
})
My features aren't refreshing as expected. What can I do?
Our SDK's implement a stale-while-revalidate approach to caching with a configurable time-to-live (TTL) value.
This means that if the feature payload is considered stale (i.e. more than the TTL amount of time has passed since it's been updated), the next request will return the stale features and refetch an update asynchronously so that on the next request, the features will be up to date. You can learn more about how our SDK's implement this in detail here.
If you would like something more real-time than this stale-while-revalidate approach, you may want to consider implementing the GrowthBook Proxy on your self-hosted instance.
How do I configure environments in the SDK?
When you create an SDK connection, it is linked to a specific environment. Learn more about environments.
How do I make my own identifier?
There are cases when using feature flags client side where the 3rd party identifiers used for assignment will be slow to load, and may cause flickering as some of the DOM rerenders. In these cases, generating your own identifier will make sure that features are assigned correctly when GrowthBook loads. This id that is generated will typically align one to one with the other identifiers, and does not need to be passed outside the SDK (though can be useful for debugging to pass this value in the trackingCallback).
The code below can be used to generate a unique user id and save it in a cookie for the maximum amount of time allowed. Note, this technique is already included with our HTML/no-code SDK. Please be aware of any cookie policies this code may impact. This id will be unique to the browser and not the user, so if a user switches devices, they will have a different id.
const getUUID = () => {
const COOKIE_NAME = "gbuuid";
const COOKIE_DAYS = 400; // 400 days is the max cookie duration for chrome
// use the browsers crypto.randomUUID if set
const genUUID = () => {
if(window?.crypto?.randomUUID) return window.crypto.randomUUID();
return ([1e7]+-1e3+-4e3+-8e3+-1e11).replace(/[018]/g, c =>
(c ^ crypto.getRandomValues(new Uint8Array(1))[0] & 15 >> c / 4).toString(16)
);
}
const getCookie = (name) => {
let value = `; ${document.cookie}`;
let parts = value.split(`; ${name}=`);
if (parts.length === 2) {
let existing = parts.pop().split(';').shift();
setCookie(name, existing);
return existing;
}
}
const setCookie = (name, value) => {
var d = new Date();
d.setTime(d.getTime() + 24*60*60*1000*COOKIE_DAYS);
document.cookie = name + "=" + value + ";path=/;expires=" + d.toGMTString();
}
// get the existing UUID from cookie if set, otherwise create one and store it in the cookie
let existing = getCookie(COOKIE_NAME);
if(existing) return existing;
const uuid = genUUID();
setCookie(COOKIE_NAME, uuid);
return uuid;
}
Below is the same code, minified:
const getUUID=()=>{const a=(a,b)=>{var c=new Date;c.setTime(c.getTime()+86400000*400),document.cookie=a+"="+b+";path=/;expires="+c.toGMTString()};let b=(b=>{let c=`; ${document.cookie}`,d=c.split(`; ${b}=`);if(2===d.length){let c=d.pop().split(";").shift();return a(b,c),c}})("gbuuid");if(b)return b;const c=(()=>window?.crypto?.randomUUID?window.crypto.randomUUID():"10000000-1000-4000-8000-100000000000".replace(/[018]/g,a=>(a^crypto.getRandomValues(new Uint8Array(1))[0]&15>>a/4).toString(16)))();return a("gbuuid",c),c};
Experiment Analysis
What is the difference between a Dimension and a Segment?
We recommend using Dimensions instead of Segments for new implementations. While Segments remain fully supported, we plan to deprecate them in a future release.
A dimension is a user attribute that can have multiple values. Some examples are country, account_type, and browser.
A segment is a specific group of users. Some examples are visitors in the US, premium users, and chrome users.
Dimensions are used to explore experiment results. For example, you can use a country dimension to see which countries had the highest conversion rates. Or an account_type dimension to see if there was a significant difference in how free vs paid users behaved. Or a browser dimension to detect any browser-specific bugs in your implementation.
Segments can apply a filter to results, usually to compensate for bad data. For example, if your experiment was only visible to premium users, but your database inaccurately shows that free users were also included, you could apply a premium users segment to only include those who were actually exposed to the test. Ideally, you could just fix the underlying data, but that's often not feasible so segments provide a quick and dirty alternative.
My old exported notebook stopped working. How can I fix it?
There's a good chance that the SQL we are exporting and your version of our Python stats library, gbstats, are out of sync.
In February of 2023 we updated our SQL engines and gbstats library to only use sums and sums of squares, rather than averages and standard deviations.
If the queries in your notebook return averages and standard deviations (using AVG and VAR SQL operators as part of the __stats CTE), then you need to run that notebook with gbstats version 0.3.1.
You can download this from PyPI using pip install gbstats==0.3.1 and ensure that your kernel uses that version of gbstats.
Ideally in this case you can redownload the notebook and use the new gbstats library (0.4.0 or newer). You can download a new notebook by navigating to your experiment in GrowthBook and clicking Download Notebook again. This should now use the updated SQL and gbstats syntax. Then, if you install gbstats 0.4.0 or later, everything should work as expected.
If the queries in your notebook return sums and sums of squares as part of the __stats CTE but your notebook is still erroring, then you probably have an old gbstats version installed and need to update to 0.4.0 or later.
You can download this from PyPI using pip install gbstats and ensure that your kernel uses that version of gbstats.
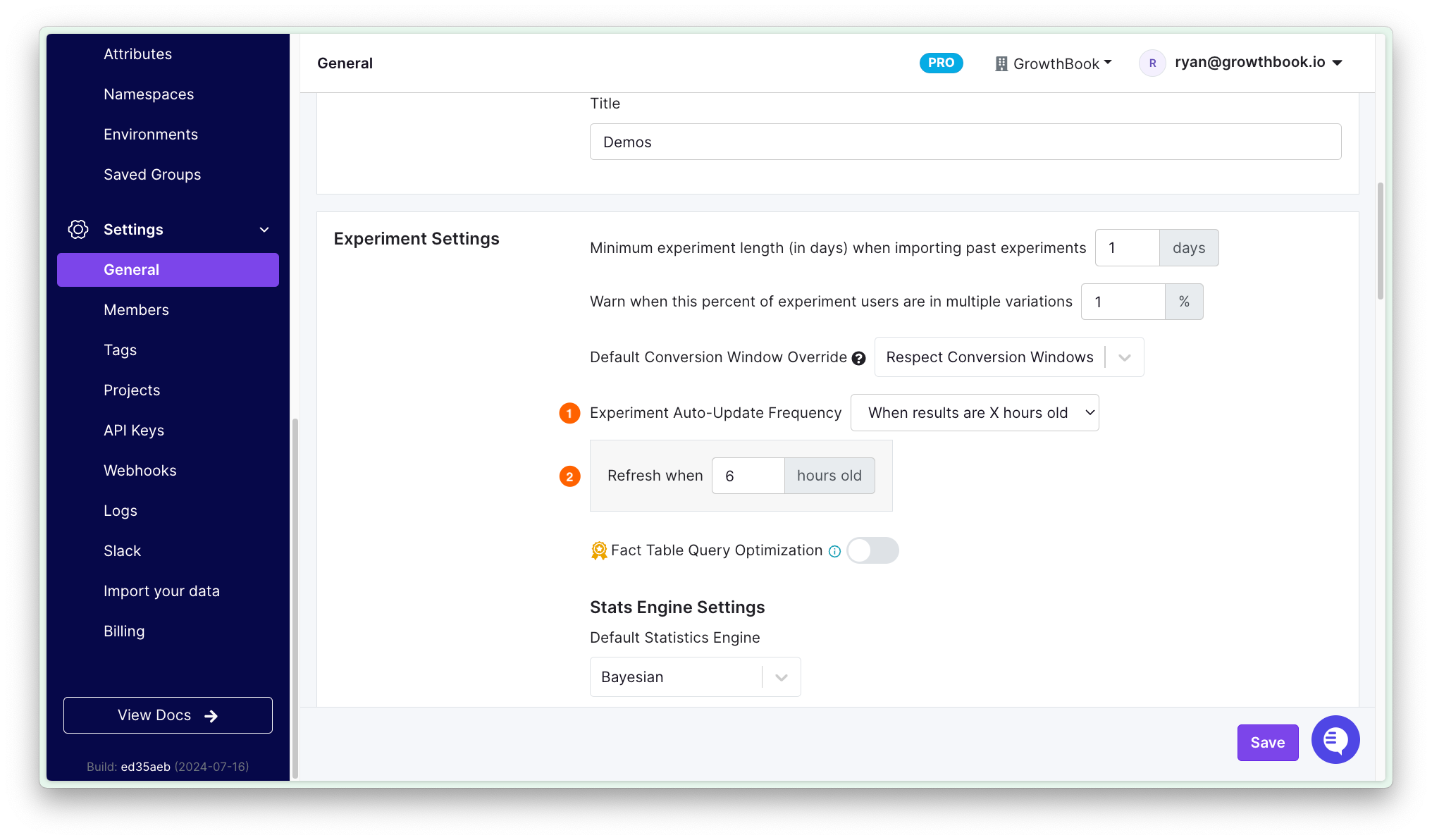
How do I update the refresh rate for experiment data?
Go to Settings → General → Experiment Settings. Change the Experiment Auto-Update Frequency field to the desired values. Save your changes.
Are users counted multiple times in the experiment results?
Deduplication ensures that each user is included only once in an experiment, even if they meet the eligibility criteria multiple times. This helps maintain accurate results and preserves data integrity.
GrowthBook achieves deduplication by assigning a unique identifier (such as a userID or sessionID) to each user. When analyzing experiment data, it records only the first instance of a user’s exposure, preventing duplicate attributions.
If a user participates in an experiment more than once (e.g., revisits the site multiple times), GrowthBook will count only their first recorded exposure.
Other
What types of SQL queries can users run in GrowthBook?
Users can only run read SELECT queries in GrowthBook. For security reasons, all user-provided SQL is validated to be a read-only query before being executed. This applies to all places where you can write raw SQL, including:
- SQL Explorer for ad-hoc queries
- Metric and Fact Table definitions
- Dimension queries
- Data Source configuration (experiment assignment queries, identifier joins, etc.)
Write operations such as INSERT, UPDATE, DELETE, etc, are not permitted from any user-entered SQL.
Some GrowthBook features, such as Pipeline Mode, may write temporary tables to your data warehouse to improve query performance. However, these write operations are managed by GrowthBook itself.
How do I disable the on-screen celebrations?
Throughout the GrowthBook application, we randomly celebrate key milestones like launching experiments with on-screen confetti. If you'd like to disable this, you can click on your avatar in the top right corner and select "Edit Profile". From there, you can disable the toggle for "Allow Celebrations". Please note this is persisted in your browser's local storage, so if you clear your browser's local storage, you will need to disable this again.
Can't find your question?
If you can't find an answer to your question above, please let us know so we can help you out and improve the docs for future users!
You can join our Slack channel for the fastest response times.
Or send an email to hello@growthbook.io if Slack isn't your thing.