Insights
Insights provide a variety of tools to help you understand your experimentation program at a glance and perform meta-analyses.
Dashboard
The Dashboard provides a high-level overview of the velocity, shipping rate, and impact of your experimentation program.
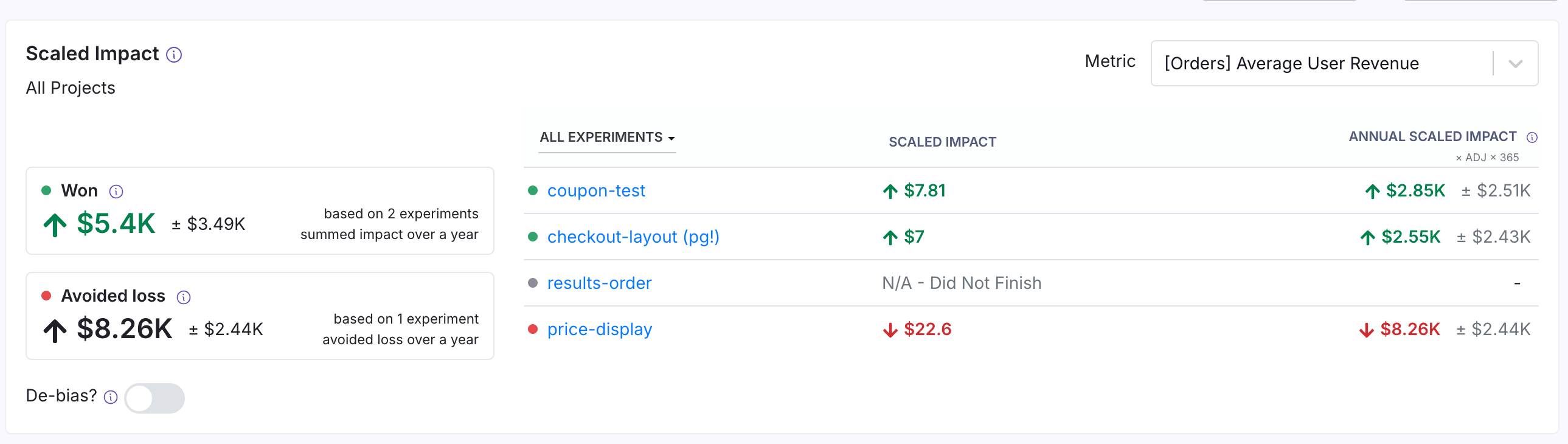
Scaled Impact
Scaled Impact provides an overview of how multiple experiments have influenced a key metric. All completed experiments that have the selected metric are included in this section.
Implementation details
For all stopped experiments that are marked as "won" or "lost," we sum the scaled impact of those experiments to present a measure of total impact.
Because some experiments have multiple variations, we only pick one variation per experiment:
- "Won" experiments use the variant selected as the winner in the experiment metadata
- "Lost" experiments use the variation that performed worst relative to the baseline.
Summing the scaled impact of "Lost" experiments helps demonstrate how experimentation provides value by preventing shipping ideas that did not pan out.
We also provide an opportunity to "de-bias" these estimates so long as there are at least 6 experiments that were stopped in this window, since simple sums of experiment impacts are subject to a variety of biases when considering total impact.
Summed experiment impact relies on several assumptions (independence of experiments, additivity of experiment impacts, and no selection bias). However, this tool should not replace accurate impact estimation via holdouts.
Details of scaled impact and de-biasing procedure
Scaled Impact
Scaled impact rescales your experiment effect to answer the question: "What would the total effect be if all participants had received a specific test variant?" For example, imagine your absolute lift in an experiment is $0.30 per user with 100 users in that variation. If your experiment got 20% of total traffic, and it was split evenly so that each variation got 50% of the experiment traffic, then the total potential traffic was 100 / (50% X 50%) = 400 users. So, the scaled impact would be $0.30 X 400 = $120. It is a simple rescaling that makes some assumptions, but it does allow you to compare the effects of experiments on different parts of your product (e.g. a big change to a small feature vs. a small change to a big feature might have the same scaled impact).
Total Impact, represented by the large Won and Avoided loss boxes, sums the effects of all experiments within a category. This assumes the effects are independent and not additive. This is not an assumption easily satisfied, but it allows you to get a general sense of scale.
De-biasing is achieved through the positive-part James-Stein shrinkage estimator, which mitigates the natural bias in experiment outcomes (where more decisive results tend to show larger effects). This estimator adjusts the results by estimating variance only from the shown experiments and shrinks all impacts toward zero. While this reduces selection bias, it does not address concerns about the independence or additivity of experiments.
Win Percentage & Experiment Status
Win percentage shows the percentage of experiments that were stopped and marked as "won."
Experiment status shows the number of experiments completed in the selected time period and represents your experimentation program's velocity.
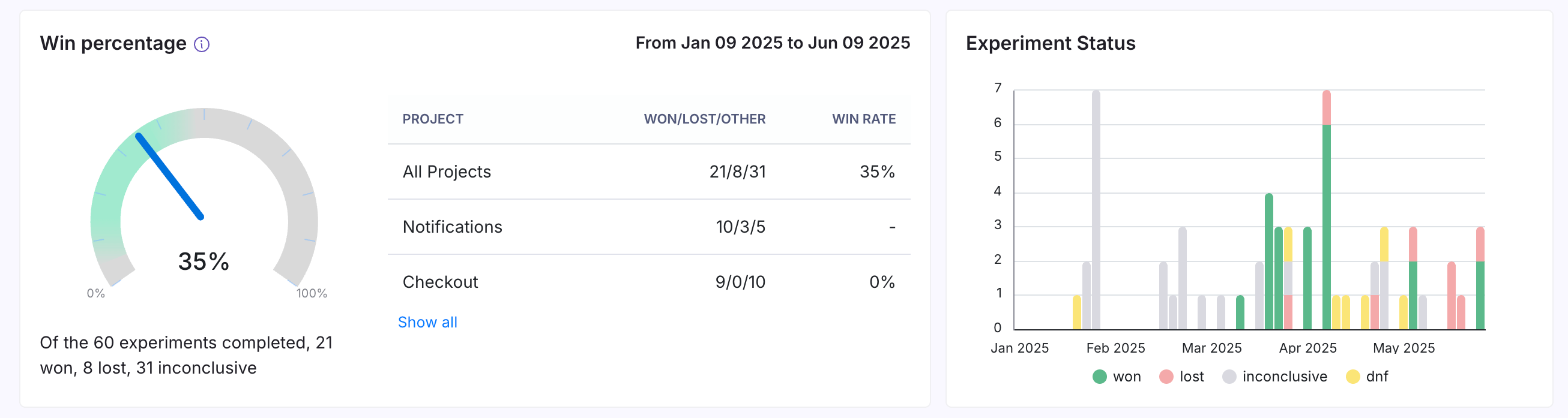
The win percentage graph is highlighted around 33% because this represents an ideal win rate for teams experimenting often. Higher win rates can suggest that you might want to be testing more ideas!
North Star Metrics
North Star Metrics are crucial, company-wide indicators of success. This panel displays how these metrics evolve over time and shows which experiments using this metric are running (or when they ended). If this panel isn't visible, go to Settings → General to set up your North Star metrics.
Learnings
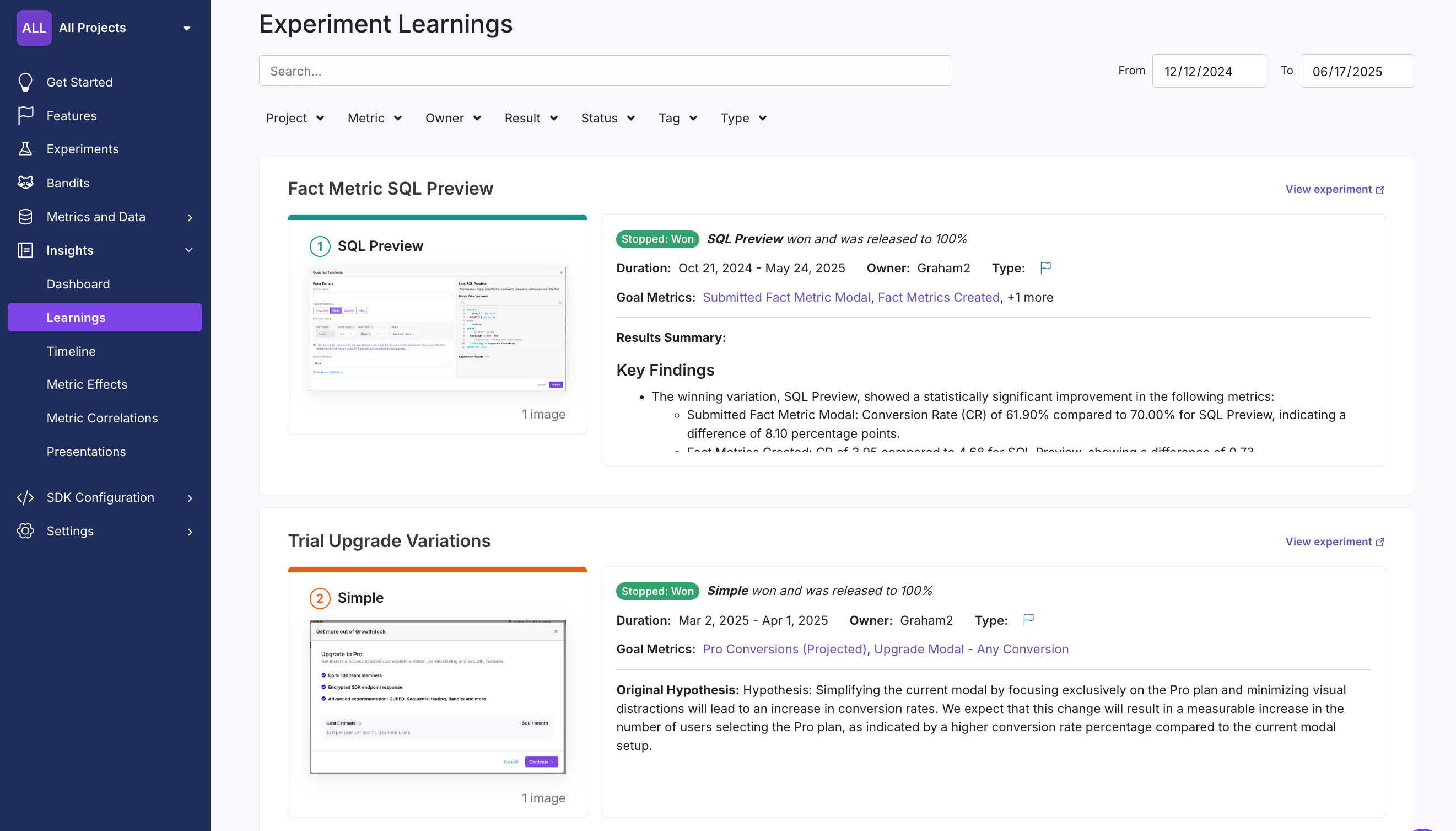
The Learnings page allows you to review all stopped experiments that match the selected filters and see:
- The experiment decision (won, lost, inconclusive)
- Screenshots of the winning variation
- Additional experiment metadata
The Learnings page provides a handy, in-depth overview of all recently completed experiments. The better the metadata input when creating and stopping an experiment, the richer the data on this page.
Timeline
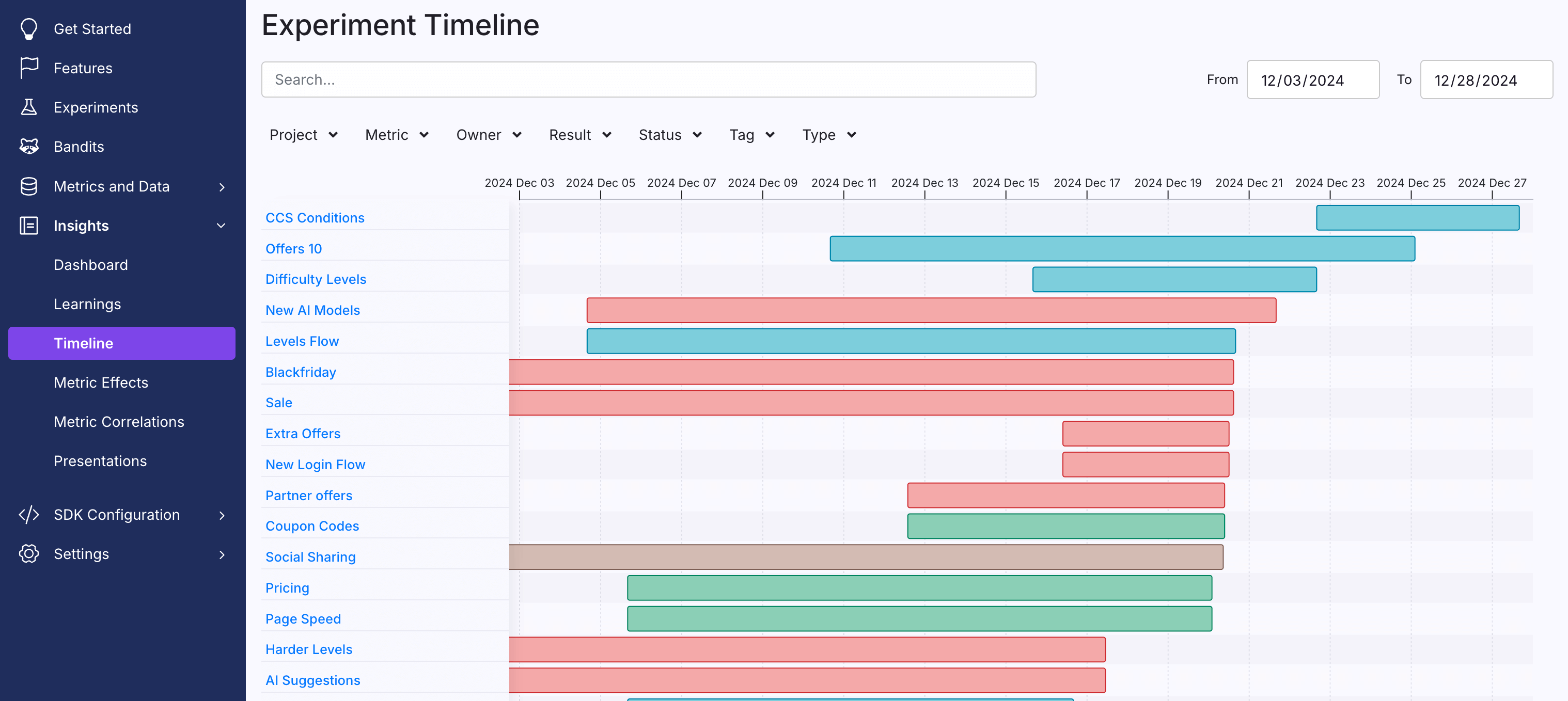
The Timeline page shows all experiments that match the selected filters, including their start and stop dates (if not still running). If an experiment had multiple phases, we place those into separate blocks on the same row.
Stopped experiments are colored to indicate whether they won (green), lost (red), or were inconclusive (gold).
Metric Effects
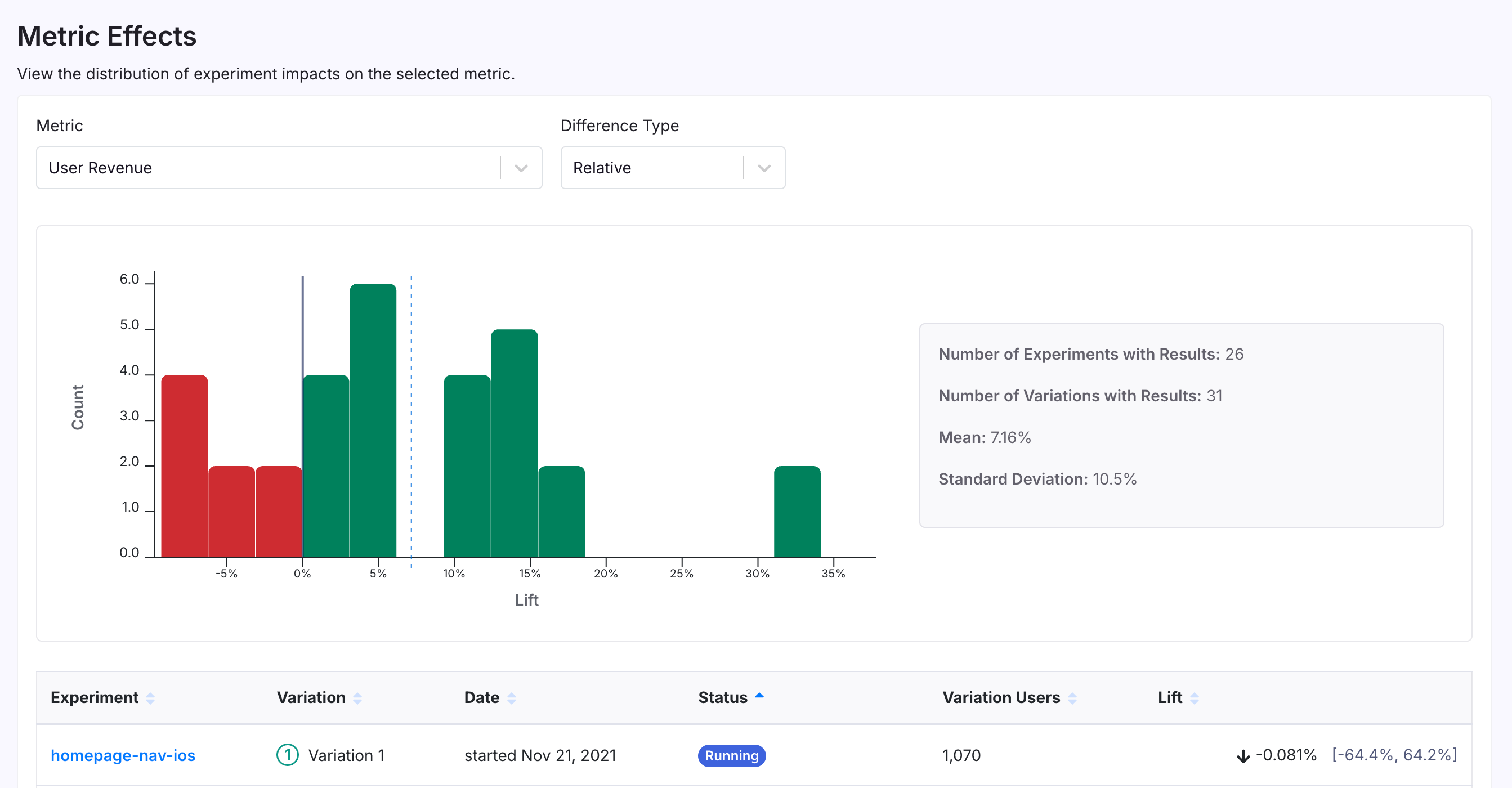
The Metric Effects page allows you to select a metric and view a histogram of experiment impacts for that metric from running and completed experiments. This shows you the typical spread of effects across your experiments, as well as providing you with historical lift data that may be helpful if using informative priors in our Bayesian engine.
Metric Correlations
The Metric Correlations page allows you to visualize how experiments tend to jointly impact two metrics. Each dot on the plot is a variation from an experiment, with the size of the dot corresponding to the number of units and the lines corresponding to the error bars.
This graph helps you answer questions like:
- When my experiments increase one metric, are other metrics following suit?
- Is there any trade-off between maximizing one key metric and another key metric?
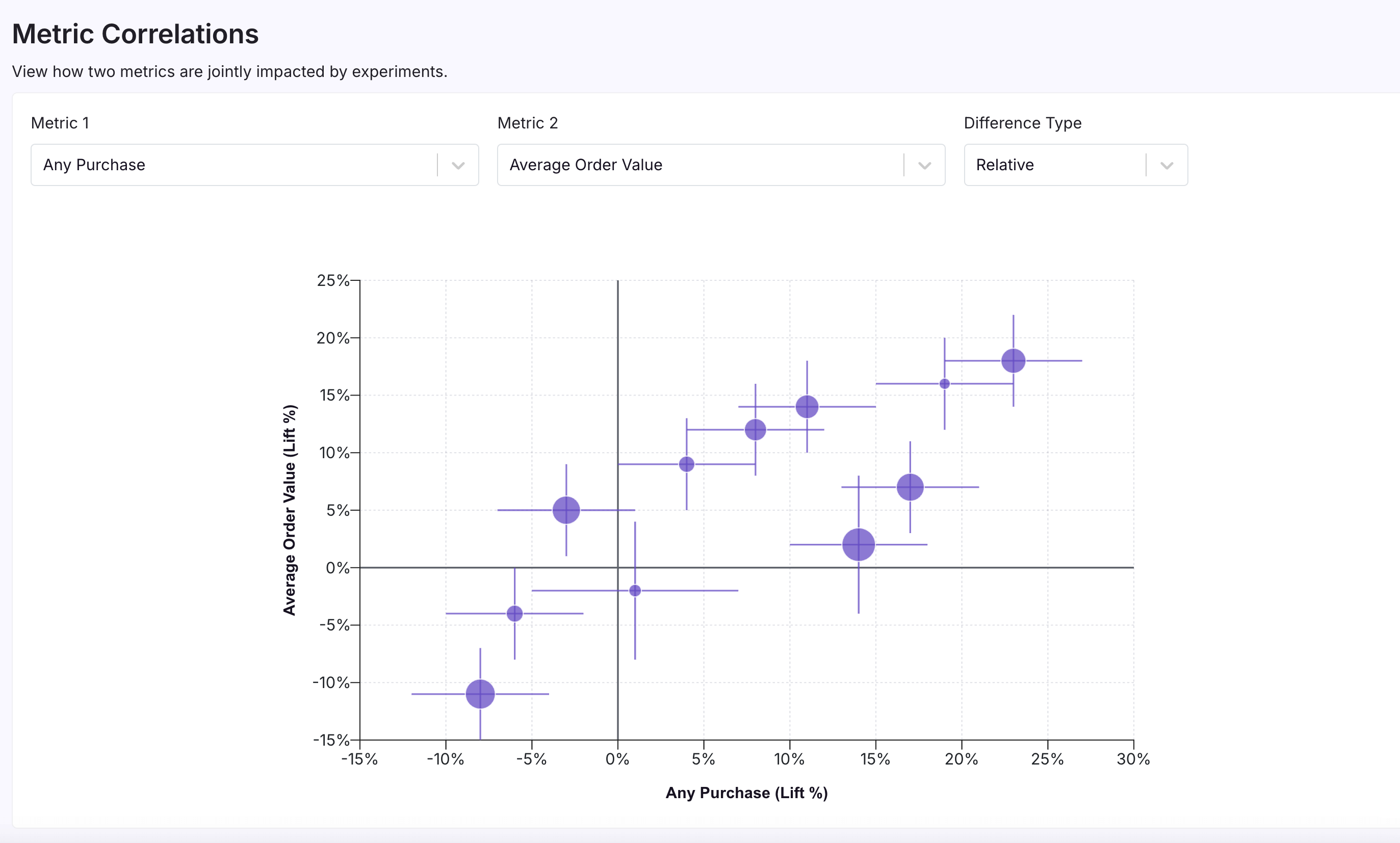
The above screenshot shows two positively correlated metrics ("Any Purchase" and "Average Order Value"). Because the dots are mostly in the top-right and bottom-left quadrants, we can see that when experiments increase the "Any Purchase" metric, they tend to also increase the "Average Order Value" metric. This means that your experiments tend to benefit or harm whether users make any purchases as well as the average value of those purchases.
The next screenshot shows a more ambiguous case (or, potentially, even a negative correlation):
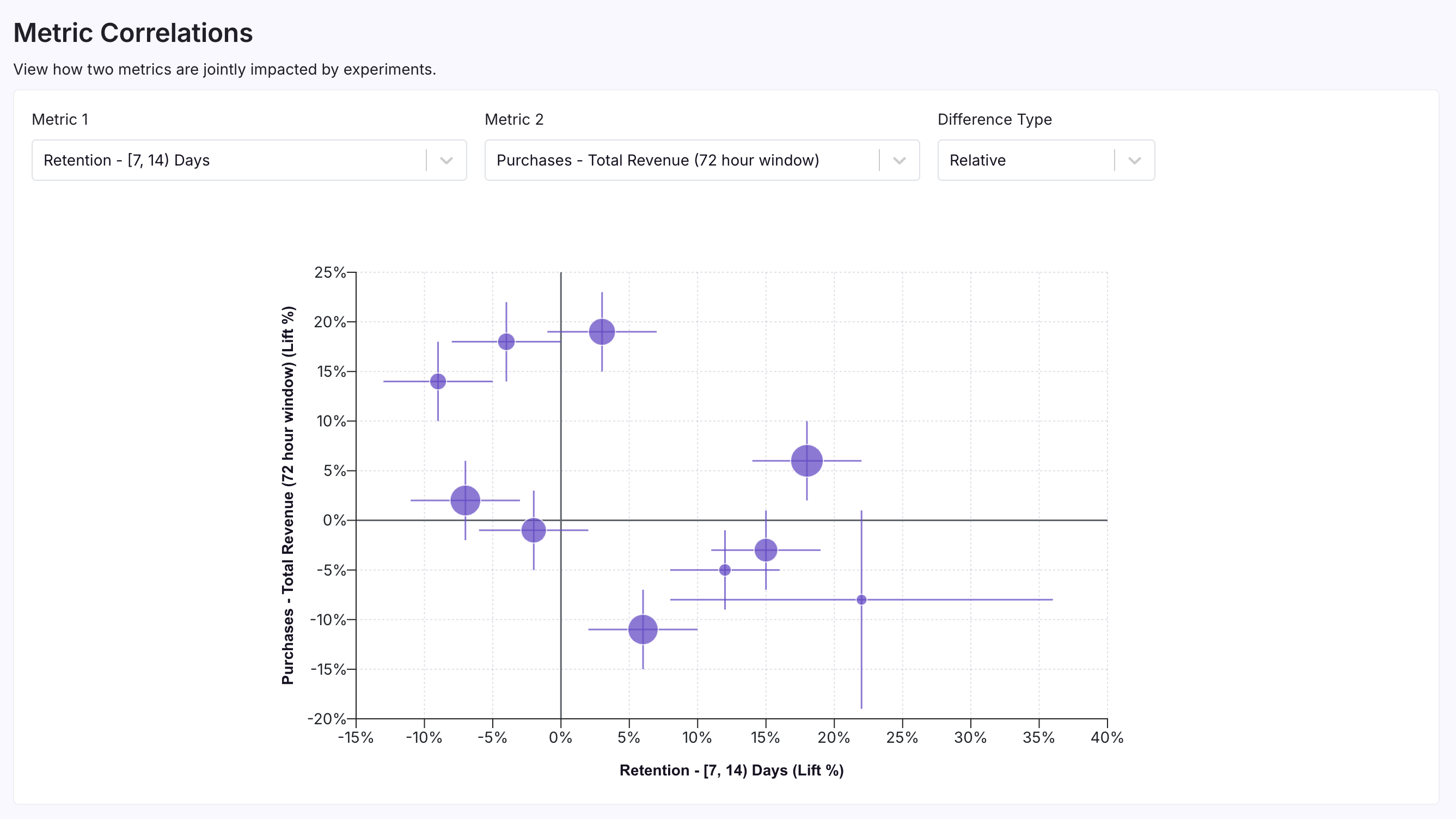
In this example, consider an app with in-app purchases. "User Retention" and "Total User Revenue" are both important as User Retention could be a leading indicator for long-run success and revenue. In this image, the effects are more scattered—or even concentrated in the top-left and bottom-right quadrants—indicating a neutral or negative correlation. This could mean there is a trade-off between maximizing revenue and keeping users engaged. This could indicate a dark pattern, where your experiments are driving purchasing behavior but somehow also making the product worse. In this situation, you'll often want to consider which goal metric is truly important and how to make trade-offs between them, or consider new experiments or features that may improve both jointly.
For a more technical discussion of this topic, read this excellent blog post by Tom Cunningham: Thinking About Tradeoffs? Draw an Ellipse.