Troubleshooting Experiments
Problem 1: No or little traffic flowing into the experiment
There are a few common reasons why there may not be any data showing in the Results tab of your experiment's detail page, first among them is a lack of experiment traffic. You'll likely see a banner like this:

Check the following to correct a lack of traffic to the experiment:
- Ensure the trackingCallback in the SDK is configured correctly. It should be using the intended tracking library (e.g. Google Analytics [GA4], Segment, Amplitude) and actually emitting tracking events to your data warehouse.
- Ensure the Hash Attribute identifier is being set for each user. When you start an experiment in GrowthBook, you need to choose which Attribute to use to assign users to variations, often the user
id. If you do not set that Attribute when you instantiate the GrowthBook SDK, then users can't be assigned to the right variation and users will default to not entering the experiment at all. - Remove any Segments or Activation Metrics that may be filtering out users. Open the Analysis Settings for your experiment and remove any selected Activation Metric or Segment. These may be filter out users. If removing them causes data to show up, you need to investigate your configuration of that Activation Metric or your Segment.
- Ensure the Experiment Assignment Query in your data source is configured correctly. You can find this query on your data source's detail page.
Problem 2: SRM errors (traffic imbalance) in the experiment
A clue that the traffic to the experiment isn't balanced is the presence of a Sample Ratio Mismatch error, shown as a warning banner at the top of the Results tab.

Whenever there is traffic imbalance in your GrowthBook experiment, the cause is usually one (or several) of these problems:
- Decoupled assignment and tracking: The experiment assignment (e.g., server-side) and exposure tracking event (e.g., client-side) are happening in different places.
- Misconfigured
trackingCallback: ThetrackingCallbackis configured to send an event to your data warehouse only under certain conditions. - Misconfigured Activation Metric: You are using an Activation Metric that is triggered differently by users across variations..
- Hash attribute mismatch: The hash attribute doesn't match the "Identifier Type" in your data source.
- Mid-experiment Targeting Changes: You made a change to the experiment targeting after it started, or created a new phase without re-randomizing.
Solution 1: Couple the tracking event with assignment
This solution addresses Problem 1: Decoupled Assignment and Tracking.
This is the most common and severe cause of SRM. While it's tempting to fire the exposure event on the frontend (e.g., "when the component is viewed") to be sure the user saw the change, this approach makes your experiment data vulnerable to a number of client-side issues:
-
Bot & Crawler Traffic: Bots will hit your server, be assigned a variation, but will never execute your client-side JavaScript code. This means that they are counted on the backend but will never fire the frontend event. Depending on your site, this can be 50% or more of traffic.
-
Ad Blockers & Privacy Tools: A large percentage of real human users (often 30-40%) use blockers that stop analytics and tracking scripts (like Segment, Google Analytics, and others) from executing. These users are also assigned but will never fire the frontend event.
-
Client-Side Factors: Normal users may bounce before the page loads, have a network error, or encounter an unrelated JavaScript error that prevents your tracking script from firing.
This massive drop-off becomes an SRM error when it is differential—that is, one variation causes more drop-off than another (e.g., the variant is 100ms slower, causing more users to bounce before the event fires).
The most robust solution is to fire your exposure tracking event from your backend, immediately after you get the variation assignment from the SDK.
This couples assignment and tracking into a single, reliable step. It completely bypasses the client-side issues, guaranteeing that every user who is assigned a variation is also counted in the experiment.
A common concern with this approach it that it "dilutes" metrics by including users who were assigned but (due to bouncing, etc.) never saw the change.
This is often a feature, not a bug! If your variant causes 2% of users to bounce because it's slow or buggy, that is a critically important negative impact of your experiment. Backend tracking correctly captures this negative impact. Frontend-only tracking hides this problem and biases your results.
If you absolutely must filter for users who saw the change, use this pattern:
-
Fire the main exposure event from the backend. This will be your reliable denominator, and it will not have SRM.
-
Fire a separate frontend event (e.g., component_viewed) when the user actually sees the component.
-
In GrowthBook, use this frontend event as an Activation Metric.
This way, your experiment's health (the SRM check) is validated on the reliable backend data, but your final metric results are filtered to only the "activated" users you care about.
Solution 2: Ensure the trackingCallback is triggered unconditionally
This solution addresses Problem 2: Biased trackingCallback Logic.
The trackingCallback you configure is used by the SDK to send tracking events to your data warehouse whenever a user is exposed to an experiment. Make sure that whether the trackingCallback method sends event data is not conditional on the experiment variation.
As you create the GrowthBook-related logic in your application code, be careful not to have users in control variations emit trackingCallbacks under more conditions than users who are not bucketed into the control variation. Otherwise, you are likely to have Sample Ratio Mismatch (SRM) issues.
It is much better to emit a tracking event as soon as possible within the trackingCallback, before doing any other custom logic that may differ across users based on the experiment variations they are exposed to.
Solution 3: Only use Activation Metrics that do not differ across variations
This solution addresses Problem 3: Biased Activation Metric.
If you are using an Activation Metric to filter users that get into your experiment analysis, you may be introducing bias if the Activation Metric is downstream of any differences between users in your variations.
Similar to the above issue where your trackingCallback fires more for users in one variation than another, if you filter out users based on some activity that differs across variations then you could be introducing bias and causing SRM errors.
The upshot is that you should not use an Activation Metric lightly. It should be a Metric that is downstream of changes to the user experience caused by the experiment. Imagine you want to check a user variation on page load, but you want to use an Activation Metric to only look at effects once users open the checkout modal where the experiment is. If you have to load more data for users in your test variation, the page may crash or be slower for those users; if this happens before you measure the Activation Metric, then you may be causing traffic imbalance as you will see fewer users in the variation in your experiment sample.
In fact, using an Activation Metric that is downstream of any difference in variations can cause bias that is not picked up by SRM errors, so you should try to avoid this whenever possible.
Best practices:
- Try not to use Activation Metrics at all, and instead only use the SDK to look up experiment membership as close as possible to the actual experiment.
- If you must use an Activation Metric, make sure it is not downstream of any differences in the user experience caused by the experiment.
- Check the Health Tab on your experiment results to see traffic breakdowns by Activation Status to help you understand what your Activation Metric is doing to your sample.
Solution 4: Ensure the Hash Attribute and Identifier Type match
This solution addresses Problem 4: Hash Attribute Mismatch.
GrowthBook randomizes users according to the Hash Attribute that you set for each user, often a user_id. When you analyze experiments, you set an "Identifier Type" that corresponds to columns in your data warehouse. Ideally, the Hash Attribute that you choose for users is both (1) logged to the data warehouse in the trackingCallback, and (2) is used as the "Identifier Type" for all of these experiments. By doing this, you establish a 1:1 relationship between the Hash Attribute and the Identifier Type.
For example, suppose you run experiments and you sometimes randomize users by device_id and sometimes randomize by user_id, setting the Hash Attribute as device_id or user_id respectively. You would set up your trackingCallback so that the Identifier Types are logged to your data warehouse with each experiment exposure.
Then, you would also have two Identifier Types in your data source, one for each Hash Attribute (device_id and user_id), and define Experiment Assignment Queries to query your data source for all the experiments of each Identifier Type.
If for some reason the Identifier in your data warehouse is different from your Hash Attribute, you could see Multiple Exposure warnings and Sample Ratio Mismatch (SRM) errors, because the ID chosen to randomize users doesn't match the ID on which queries are running in your data warehouse. You would fix this so that there is a 1:1 mapping between the Identifier and Hash Attribute by ensuring the Hash Attributes are always emitted to the data warehouse, and use set these values as the Identifier Types in GrowthBook.
Why might the Hash Attribute and Identifier Type be different?
There are times where it might be beneficial to have the Hash Attribute differ from the Identifier Type. The consequence is that there may be minor traffic imbalance or Multiple Exposures, but you may be willing to accept some slippage in the 1:1 mapping between Identifier Type and Hash Attribute in order to more easily join experiment exposure data with metric data.
For example, on client-side experiments with Google Analytics (GA4), you may wish to avoid flickering by hashing on some custom ID as we do in our Script Tag SDK and not wait for the IDs provided by GA4.
While you could send this custom ID in your trackingCallback you may prefer to use GA4 identifiers as the Identifier Type instead, because they are already tracked with many of the other GA4 events that you are using as Metrics.
Solution 5: Minimize Experiment targeting changes while running
This solution addresses Problem 5: Mid-experiment Targeting Changes.
When you make changes to the targeting of an experiment or created a new phase without re-randomizing users, it's possible that the traffic to the experiment will become imbalanced. This is because the users who were already in the experiment may continue to be in the same variation at differing rates. Whenever creating a new phase, you should re-randomize traffic when possible, and only certain changes to an experiment's targeting conditions can be done without re-randomizing.
You can read more about the rules for changing experiment targeting and carryover bias in our documentation.
If your experiment is suffering from these issues, unfortunately the only solution may be to restart the experiment (you can do this by creating a new phase and choosing to re-randomize traffic). Of course, some amount of bias and SRM may be preferable to throwing out your data, but this depends on the magnitude of the problem.
Solution 6 (URL Redirects): Ensure trackingCallback fires
If you're seeing SRM warnings while running a URL Redirect test, especially if you are using a front-end SDK such as the HTML, JavaScript, React, or Vue.js SDKs, please review the Sample Ratio Mismatch (SRM) Warnings on URL Redirect Tests documentation.
Problem 3: Multiple Exposures
We default to allowing 1 percent of units (e.g. users) in an experiment have multiple exposures without raising a warning due to the fact that many experimenters have slight mismatches in hashing attributes and warehouse tracking that can cause minor errors. You can adjust this in your organization settings under Settings > General > Experiment Settings.
If you have multiple exposure errors, the issue is fundamentally caused by a mismatch between the attribute that you are randomizing on (your "hash attribute") and the identifier being stored in your data warehouse. You can read more about this problem and how to solve it here.
Another potential issue is that you made unsafe changes to your experiment targeting and randomization. We attempt to prevent this by having a curated flow for making changes, but we provide you with flexibility to make a whole host of changes that could result in multiple exposures if you choose to override our warnings. You can read more about our rules for changing experiments while running here.
Problem 4: Metric averages don't look as expected
It's important to ensure that the Metric values in the baseline and variation are what you would expect. This helps confirm that the Metrics are set up correctly and that they are joining properly to the Experiment Assignment Queries.
In the image below, notice that the values look like reasonable, per-user averages. If there is no data or if the values are very different from what you'd expect, consider the solutions below.

Solution: Understand the experiment's population
Sometimes the Metric values in an experiment may surprise you if you are targeting an experiment to new users (values may be low!) or power users (values may be high!). Each experiment can have different targeting Attributes, and it is totally possible that the values are representing that experiment's population. Consider this before launching into in-depth investigations of your Metric's set-up.
Solution: Check the Metric's configuration
You can confirm that the Metric is returning the right values in the table rows on a per-user basis. Navigate to the Metric page, edit the SQL for the Metric, and use the Edit SQL interface to run test queries and make modifications to make sure the rows you are getting are what you expect. The results should show the right identifiers, timestamps, and values.
You should also make sure the Metric Window is not too short and not too long, otherwise it could be excluding or including too much data.
Solution: Make sure your Identifier Types are correct
If you are seeing some users flow into your experiment but aren't seeing any Metric data, you should ensure that the Metric data is able to join to your experiment exposure data.
This is illustrated in the image below. Notice the 38,919 total users in the upper left corner, but no data in the "Baseline", "Variation", or "Chance to Win" columns:

GrowthBook relies on the Identifier Type in your data source to merge users in your experiment with Metric values. This is accomplished through the Experiment Assignment Query (for users) and the Metric (for Metric values). These Identifier Types must be the same, or linked by a Join Table, to run a query in GrowthBook. While we actually will throw an error if you can't join them, you may still have set up one or the other incorrectly to point to the wrong column, or the data in the columns for your Experiment Assignment Query and Metric may not overlap. It's a good idea to ensure that the values being produced by both queries are what you expect.
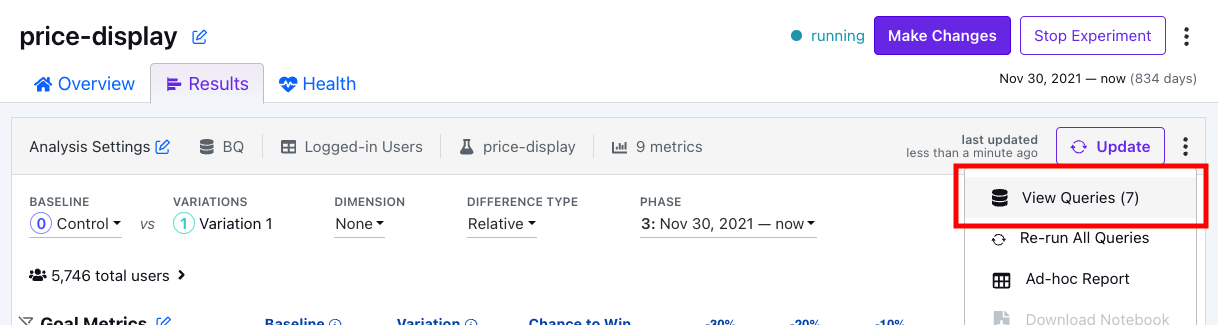
Solution: Understand the overall query logic better
You can view the queries generated by GrowthBook by navigating to the experiment's Results tab, looking on the right side of the page (shown below) and clicking "View Queries". You can then use parts of these queries and debug them by running raw SQL in your own data warehouse to make sure that your configuration is correct.