This page is unlisted. Search engines will not index it, and only users having a direct link can access it.
Technical power details
Here we document the technical details behind GrowthBook power calculations and minimum detectable effect (MDE) calculations for both frequentist and Bayesian engines.
Below we describe technical details of our implementation. First we start with the definition of power.
Power is the probability of a statistically significant result.
We use the terms below throughout. Define:
the false positive rate as α (GrowthBook default is α=0.05).
the critical values Z1−α/2=Φ−1(1−α/2) and Z1−α=Φ−1(1−α) where Φ−1 is the inverse CDF of the standard normal distribution.
the true relative treatment effect as Δ, its estimate as Δ^ and its estimated standard error as σ^Δ. Note that as the sample size n increases, σ^Δ decreases by a factor of 1/n.
We make the following assumptions:
equal sample sizes across control and treatment variations. If unequal sample sizes are used in the experiment, use the smaller of the two sample sizes. This will produce conservative power estimates.
equal variance across control and treatment variations;
observations across users are independent and identically distributed;
all metrics have finite variance; and
you are running a two-sample t-test. If in practice you use CUPED, your power will be higher.
For a 2-sided test (all GrowthBook tests are 2-sided), power is composed of the probability of a statistically significant positive result and a statistically significant negative result. Using the same algebra as in Equation 1 (except using Z1−0.5α for the critical value), the probability of a statistically significant positive result is
πpos=1−Φ(Z1−α/2−σ^ΔΔ).
The probability of a statistically significant negative result is
Some customers want to know what effect size is required to produce at least π power.
The minimum detectable effect is the smallest Δ for which nominal power (e.g., 80%) is achieved.
Below we describe commonly used MDE calculations, though we do not use these at GrowthBook.
For a 1-sided test there is a closed form solution for the MDE.
Solving Equation 1 for Δ produces
MDE=σ^Δ(Φ−1(1−α)−Φ−1(1−π)).
In the 2-sided case there is no closed form solution.
Often in practice the MDE is defined as the solution to inverting Equation 2.
This ignores the negligible term in Equation 3, and produces power estimates very close to π:
MDEtwo-sided=σ^Δ(Φ−1(1−α/2)−Φ−1(1−π)).
This approach works when effects are defined on the absolute scale, where the uncertainty of effect estimate does not depend upon the true absolute effect.
For relative inference, this does not hold, and so GrowthBook uses a different approach. The terms below are used to help define the variance of the sample lift.
Define ΔAbs as the absolute effect.
Define μA as the population mean of variation A and σ2 as the population variance.
For variation B analogously define μB; recall that we assume equal variance across treatment arms.
Define N as the per-variation sample size.
Define the sample counterparts as (μ^A, σ^A2, μ^B, and σ^B2).
Therefore, when inverting the power formula above to find the minimum Δ that produces at least 80% power, the uncertainty term σ^Δ changes as Δ changes.
To find the MDE we solve for the equation below, where we make explicit the dependence of σ^Δ on Δ:
σ^Δ(Δ)Δ=Φ−1(1−α/2)−Φ−1(1−π).
Define the constant k=Φ−1(1−α/2)−Φ−1(1−π).
We solve for μB in:
Similarly, the MDE returned can be negative if the denominator is negative, which is nonsensical.
We return cases only where the denominator is positive, which occurs if and only if:
The condition in Equation 10 is stricter than the condition in Equation 9.
In summary, there will be some combinations of (μA,σ2) where the MDE does not exist for a given N. If α=0.05 and π=0.8, then k≈2.8. Therefore, a rule of thumb is that N needs to be roughly 9 times larger than the ratio of the variance to the squared mean to return an MDE. In these cases, N needs to be increased.
To estimate power under sequential testing, we adjust the variance term σ^δ to account for sequential testing, and then input this adjusted variance into our power formula.
We assume that you look at the data only once, so our power estimate below is a lower bound for the actual power under sequential testing.
Otherwise we would have to make assumptions about the temporal correlation of the data generating process.
In sequential testing we construct confidence intervals as
Δ^±σ^∗N∗N2ρ22(Nρ2+1)log(αNρ2+1)
where
ρ=N∗−2log(α)+log(−2log(α)+1)
and N⋆ is a tuning parameter.
This approach relies upon asymptotic normality.
For power analysis we rewrite the confidence interval as
For Bayesian power analysis, we let users specify the prior distribution of the treatment effect.
We then estimate Bayesian power, which is the probability that the (1−α) credible interval does not contain 0.
We assume a conjugate normal-normal model, as follows:
ΔΔ^∣Δ∼N(μprior,σprior2)∼N(Δ,σ^Δ2).
In words, the model has two parts: 1) the normal prior for the treatment effect, which is specified by you; and 2) conditional upon the treatment effect, the estimated effect is normally distributed.
The normal prior has several advantages, including: 1) bell-shaped distribution around the prior mean, so that extreme estimates will be shrunk more towards the prior than moderate estimates; 2) the ability to specify two moments, which is often the right amount of information for a prior; and 3) simplicity.
The conditional normality of the effect estimate is motivated by the central limit theorem.
We use the normal distribution below to approximate the posterior:
This is an approximation to the posterior because Δ affects σ^Δ2. We tested this approximation through extensive simulations, and found it had comparable coverage and mean squared error to a posterior distribution empirically sampled using Metropolis Hastings.
We define rejection as the 100(1−α)% confidence interval not containing zero.
For our posterior approximation, this occurs if the posterior mean for Δ∣Δ^ (i.e., Ω−1ω) divided by its posterior standard deviation(i.e., Ω−1) is beyond the the appropriate critical threshold Z⋆ (e.g., Φ−1(0.975) for α=0.05).
Inside of a Bayesian framework, it can help to permit the case where the prior model is misspecified.
That is, the prior specified by the customer differs from the true prior that generates the treatment effect.
We permit misspecification of the prior for Δ, as we assume that the true data generating process (DGP) is Δ∼N(μ⋆,σ⋆2), while the specified DGP has Δ∼N(μprior,σprior2).
We assume the prior is specified on the relative scale.
In derivations below we use the marginal distribution of Δ^, which we find using its moment generating function:
In practice GrowthBook assumes there is a true fixed effect size, i.e., the variance of the data generating process σ⋆2 equals 0, and μ⋆=Δ, so two-sided power is
We assume that σ⋆2=0 for simplicity and because large values of σ⋆2 can result in negative MDEs (see here).
If the prior variance σprior2 equals infinity then Equation 11 reduces to Equation 4.
MDEs are not well defined in the Bayesian literature.
We provide MDEs in Bayesian power analysis for customers that are used to conceptualizing MDEs and want to be able to leverage prior information in their analysis.
We could define the MDE as the minimum value of μ⋆ such that at least π power is achieved.
This definition is Bayesian in that it permits uncertainty in the parameters in the data generating process.
However, if σ⋆2 is large, then there are some combinations of parameters where the MDE can be negative.
That is, negative values of μ⋆ result in power being at least π.
Usually the inferential focus is the true treatment effect for the experiment (Δ), not the population mean from which Δ is just one realization (μ⋆), so we set σ⋆2=0 and consequently, Δ=μ⋆.
This is why in practice we frame our Bayesian MDE as, ``given our prior beliefs and the data generating process, what is the probability we can detect an effect of size Δ?'', where Δ is a fixed number.
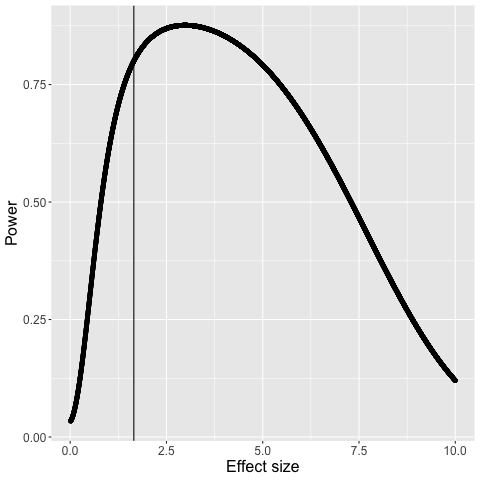
Another subtlety is that for a fixed sample size, Equation 11 can be decreasing in effect size, illustrated by Figure 1.
Figure 1
Figure 1 shows the case where the group sample sizes are 1500, the data mean is 0.1, the data variance is 0.5, the specified prior mean μprior=0.1, the specified prior variance σprior2 is 0.3, and the variance of the data generating process σ⋆2 is 0.
Nominal 80% power occurs at 1.65, continues to increase in effect size until the effect size is about 3, and then begins decreasing.
Power decreases in effect size because the variance in Equation 8 is quadratic in effect size, and in Equation 11 the term in front of Z1−α/2 goes to infinity as Δ gets large.
The coefficient in front of Z1−α/2 in Equation 4 is 1, so frequentist power is increasing in effect size in all cases.
Monotonicity does hold for Bayesian power for absolute effects, where the variance is not affected by the effect size.
Because power is not monotonic in effect size, we perform a grid search across effect sizes ranging from 0 to 500%.
The derivative of Equation 11 is bounded in absolute value by 2ϕ(0)<0.8, where ϕ(.) is the density of the standard normal distribution.
Let the length of one grid cell equal l.
We evaluate power at the points {0,l,2l,...,5−l,5}.
Suppose the power at the kth gridpoint is πk, k>0.
Because 1) the maximum slope from the midpoint to the endpoint of the cell is no greater than 2ϕ(0); and 2) the maximum distance from where power is evaluated is l/2, the maximum power in [(l−1)k,lk] is no greater than max(πk−1,πk)+ϕ(0)l.
Motivated by this fact, we describe our approach in Algorithm 1.
In words, Algorithm 1 evaluates power at Δ={0,0.001,0.002,...5}, until it finds the first element k such that π(k)>=π−ϕ(0)l.
If power exceeds this threshold, then we evaluate a finer grid across the range from [k−l,k], where the grid cell length is l′<<l.
We find the first element (if it exists) of this finer grid where power is at least π.
We return this first element as the solution if it exists; otherwise we keep searching the coarse grid.
Algorithm 1
Define l as the length between points at which power is evaluated (l=0.001 in production).
Define the grid of points between 0 and 5 as G={0,l,2l,...,5−l,5}.
Begin evaluating π(k) for k∈G.
If π(k)<π−ϕ(0)l for all k, then the MDE does not exist. Otherwise:
Find the first k∈G such that π(k)>=π−ϕ(0)l.
Define l′ as a finer grid resolution (in production, l′=l/100).
Find the first element of the set {k−1,k−1+l′,k−1+2l′,...,k−l′,k} such that power evaluated at that point is at least π.
If no such point exists, return to the coarser grid search in Step 3.
If power exceeds π+ϕ(0)l′ at any point in [0,5], then Algorithm 1 is guaranteed to detect it.
In practice we use l=10−3 and l′=10−5.