GrowthBook Best Practices
Organization
As you scale up your usage of GrowthBook and start running many experiments, keeping everything organized and easy to find is essential. GrowthBook includes a number of organizational structures to help you scale.
Organizations
The organization is the highest level structure within GrowthBook. An organization contains everything within your GrowthBook instance: users, data sources, metrics, features, etc. For both cloud and self-hosted users, it is possible for users to join multiple organizations. Users can belong to multiple organizations, but each organization is otherwise entirely independent of the others. For some, complete isolation of the teams or subdivisions within the company may be desired. For example, if your company has two or more largely independent products (e.g., Google has Search and Google Docs), you can set up multiple organizations per product.
For self-hosted enterprise users, we support multi-organization mode, which also comes with a super-admin account type that can manage users across organizations.
Environments
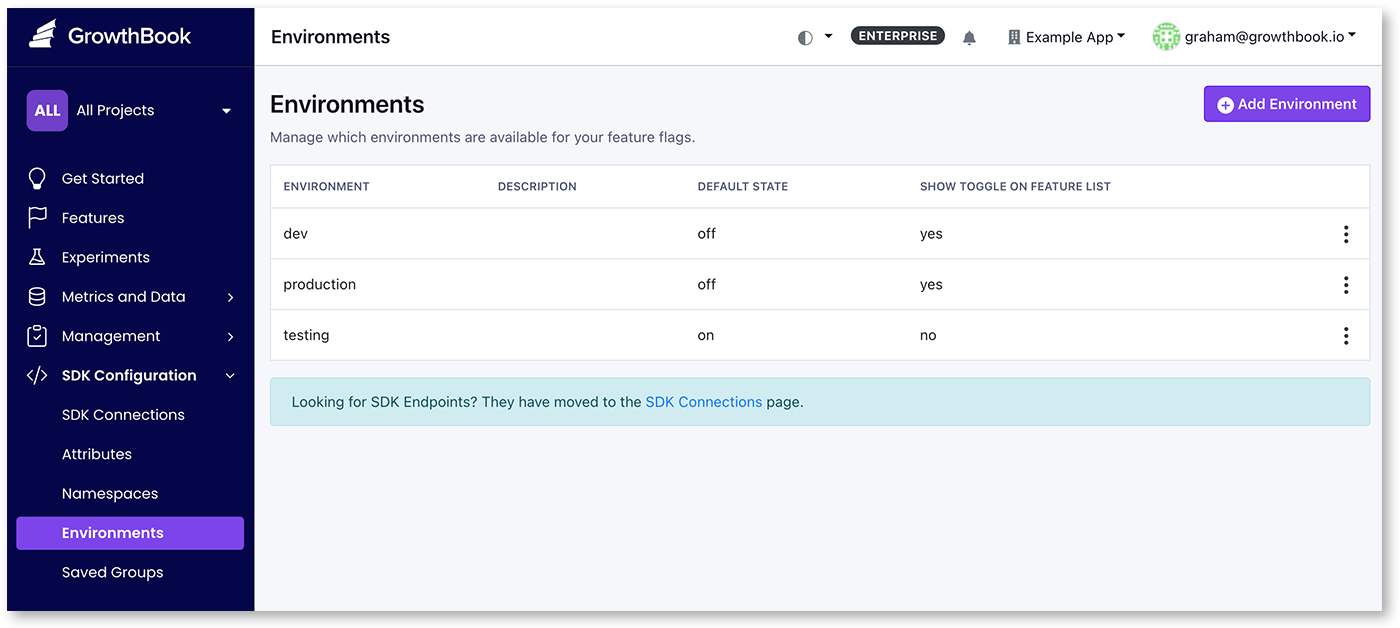
In GrowthBook, you can create as many environments as you need for feature flags and their rules. Environments are meant to separate how your feature flags and rules are deployed. Each environment can have one or more SDK API endpoints specified when you create the SDK, allowing you to differentiate the rules by environment. For example, you might have environments for “Staging”, “QA”, and “Production”. While testing the feature, you can set specific rules to on the "development" or "QA" environment, and when you're ready, you can move applicable rules to the "production" environment.
You can add an arbitrary number of environments from the SDK Connections → Environments page.
Projects
Within an organization, you can create projects. Projects can help isolate the view of GrowthBook to just the sections that apply for that GrowthBook user. Projects are a great way to organizationally separate features, metrics, experiments, and even data sources by team or product feature. For example, you could have a project “front-end” and one for “back-end”, or by team like “Growth” and “API”. Unlike separate organizations, projects can share data. Projects are managed from the Settings → Projects page.
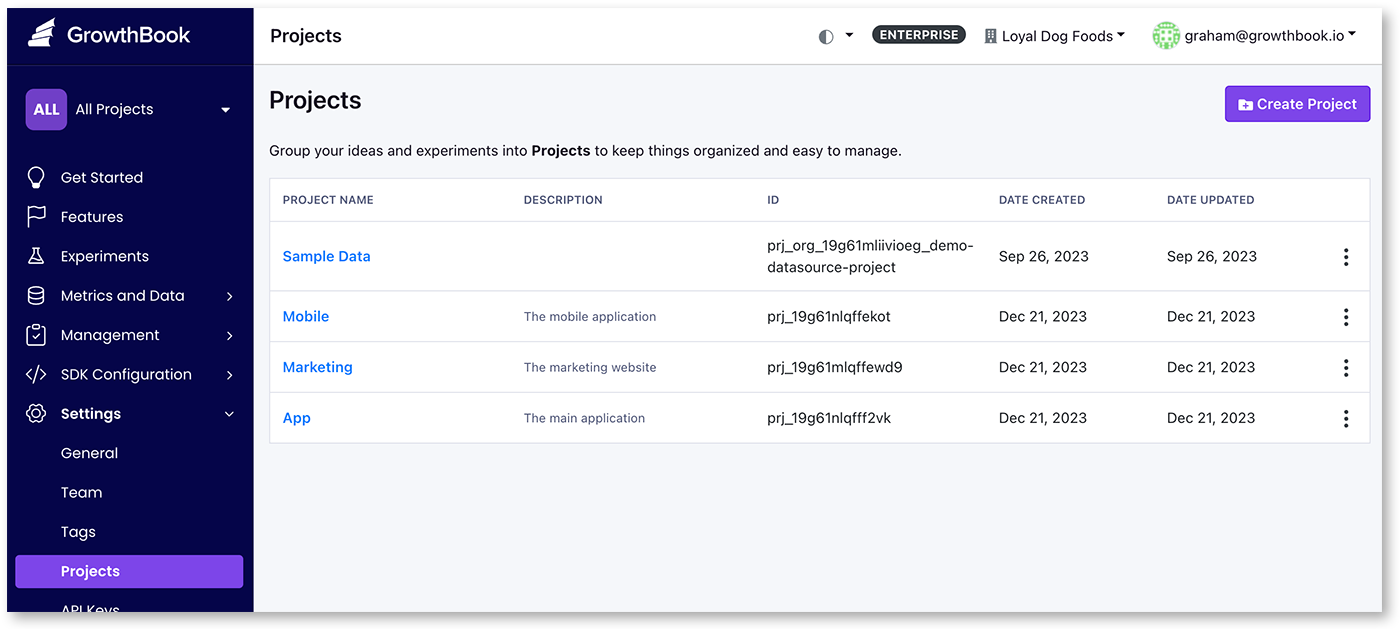
A use case for using projects is if you have divisions within your product but a centralized data source. We typically see projects used per team or per project within your organization. For example, if you have a mobile app and a website that shares users, but the code bases are different, you will want to create two projects: a mobile project and a web project.
Each of the items within GrowthBook can be assigned to multiple projects. You can have a data source that is part of the ‘mobile’ and ‘web’ projects but not to a ‘marketing’ project. That data source will not be available for users in the 'marketing' project.
To help keep feature payloads smaller, the SDK endpoint where the feature definitions are returned can be scoped to each project. If using Projects based on features or area of your product, you can use this feature to only return features that pertain to that area. For example, with our “mobile” and “website” example, you can add the project scope to only return features for the project as these are likely to use different code than the other, and you don’t want to expose features unnecessarily.
One advantage of using projects is that you can adjust permissions and even some statistical settings per project- users can have no access to a project or, inversely, have no general permissions but add a project permission so they can work within their project. If a team prefers to use a frequentist statistical model, this can be adjusted per project.
Tags
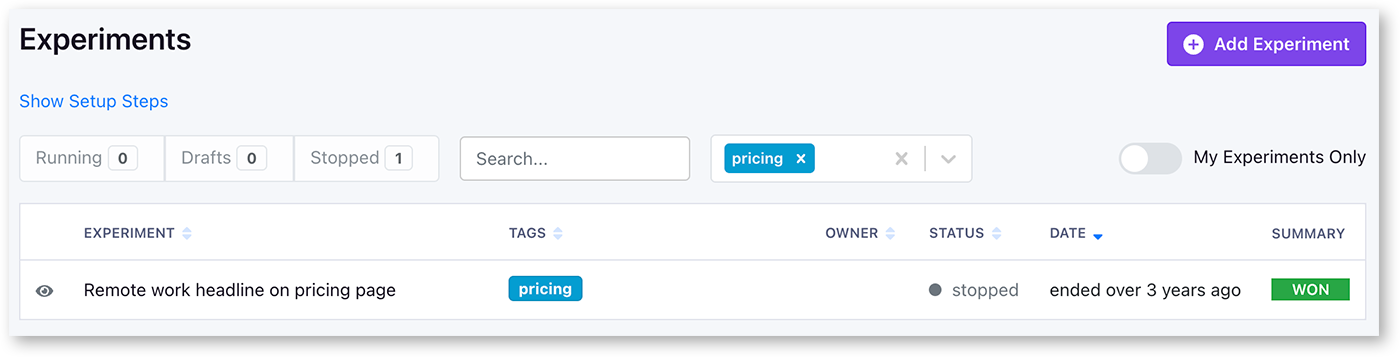
Another way to organize GrowthBook is with tags. With tags, you can quickly filter lists, and select metrics. For example, if you tagged all experiments to do with your checkout flow with the tag “checkout”, you can quickly see this in the list by clicking on ‘filter by tags’ on the experiment list. Tags can be color-coded and managed from our Settings → Tags page. You can add multiple tags per item you are tagging.
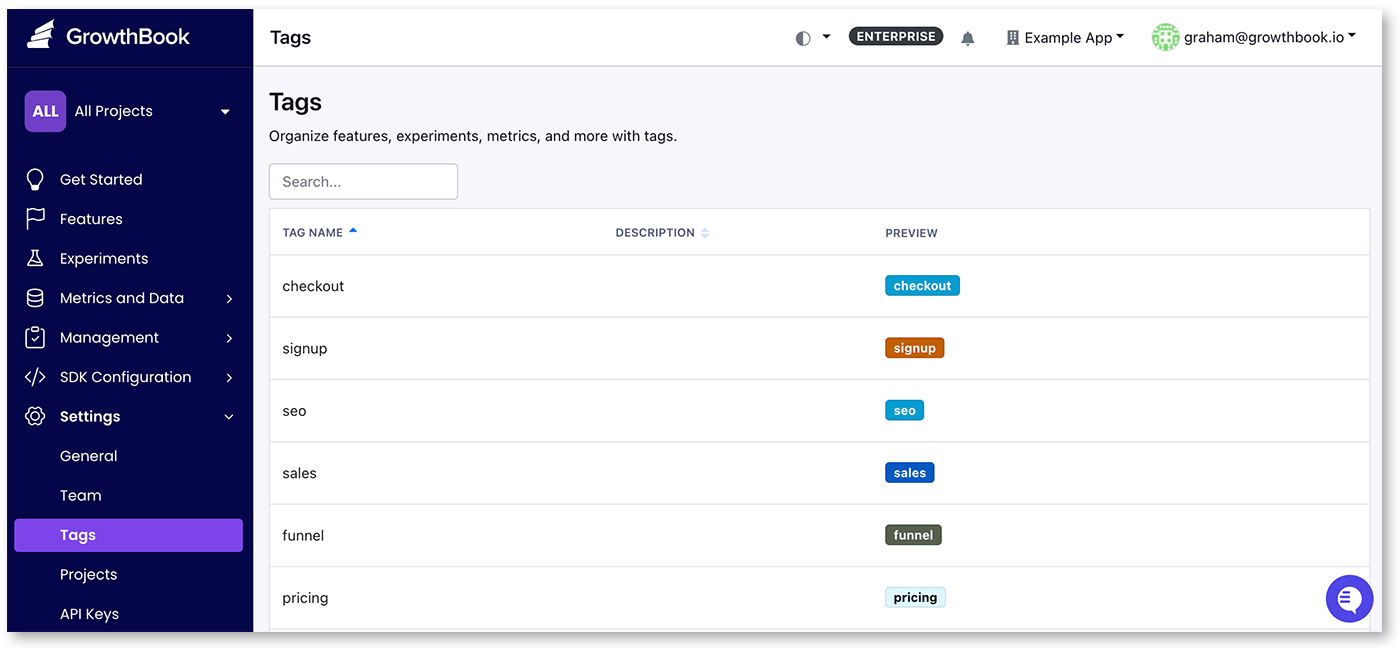
Metrics with tags can be used to quickly add all those metrics to an experiment. When creating an experiment or editing the metrics, there is a section titled “Select metric by tag” which will let you add all the metrics by the tag name to guardrail, secondary, and/or goal metrics. This is useful if you want to use a standard set of metrics for your experiments.
Tags are often used to mark sub-features of your product; for example, if you have an e-commerce website, you might want to tag features or experiments with the area they affect, like ‘pricing,’ ‘product page,’ or ‘checkout.’
Naming
Another organizing principle you can use is the naming of your experiments and features. Because GrowthBook makes it easy to quickly search the list of features and flags, using naming conventions can be an effective way to organize your project.
We’ve seen several strategies be successful here, but as a general rule, you’ll want to be as specific as possible with naming features and experiments. For example, you can use <project scope>_<project name> or the year, quarter, or section plus the name of the experiment, e.g.: “23-Q4 New user registration modal“ or “23-Team3 Simplified checkout flow”. This lets you quickly see when the experiment was run or which team worked on it.
Hygiene & Archiving
As the number of features and experiments grows, you will want to remove past items that are no longer relevant. Within GrowthBook you can archive and delete. Deleting something will permanently remove items from GrowthBook. Archived items in GrowthBook won’t be deleted, but they are removed from the main part of the UI and not available for adding to new experiments (for archived metrics). Archived items can also be restored at any time. These methods help you keep your UI clean and relevant.
Source of Truth
If you run an experimentation program for a long enough time, you’ll find yourself with an experiment idea that seems really familiar, and people will wonder, “Didn’t we already test this?” If you don’t have a central repository for all your experiment results, it can be difficult to find if you did test this previously, and even if you did, if what you tested was similar enough to the new idea not to have to test it again.
GrowthBook is designed to help with this by creating a central source for the features you’ve launched and the experiments you’ve run. To help facilitate this, GrowthBook has created a number of features to help you capture meta information.
Meta Information
Features and experiments can all have metadata attached to them. The purpose of this is to help capture all the meta-information around a feature or experiment that might help contextualize it for posterity and help capture the institutional knowledge that your program generates. This is also very helpful when new members join your team, so they don’t just suggest ideas you’ve run many times already.
By default, GrowthBook has fields for a description, hypothesis, and tags. The description is a free-form text field, and meant to capture the broader context of the feature or experiment. The hypothesis is a structured field that is meant to capture the specific hypothesis you are testing with the experiment. The tags are a way to categorize the feature or experiment. You can add multiple tags to each item.
For experiments, you should capture the original idea, any screenshots of similar products, and, most importantly, capture images/screenshots of the control and variants for the experiment. Quite often, someone will suggest an idea you’ve run previously. In these cases, it is vital to be able to find out what exactly you tested previously - it's possible that the new idea is slightly different, or you may decide that it is the same and try testing another idea, or you could decide that your product is substantially different, and the same idea may be worth testing again. To make this decision, it is essential to capture not just the experiment results but the broader context of what your product looked like at the time and the test variants.
Getting your team to document is always a challenge. GrowthBook takes two approaches to help with this. The first is to make it super easy to add documentation directly in the platform you’re already using for the experiment. Secondly, we added launch checklists, which require completing certain tasks before your team is able to start an experiment.
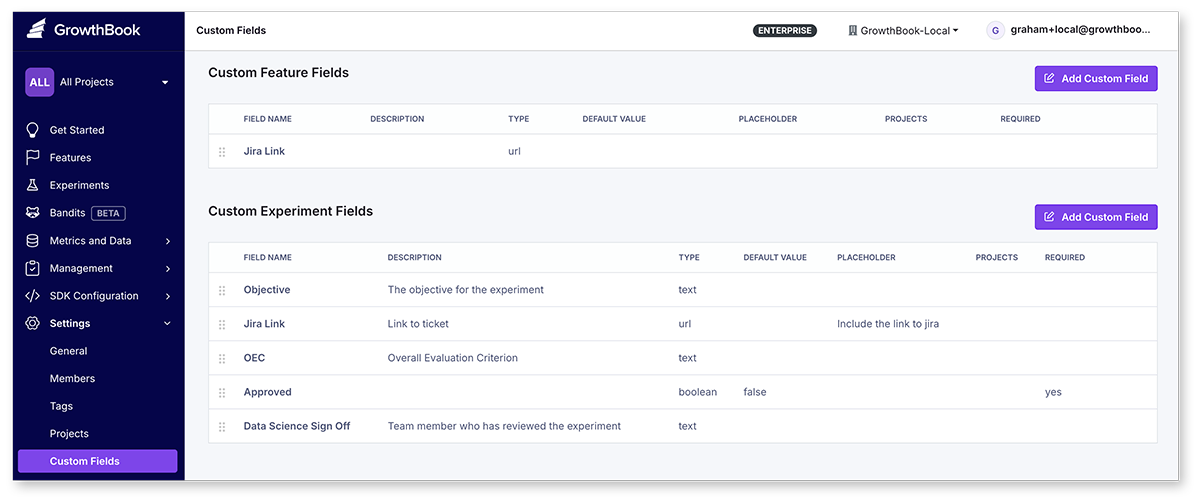
Custom Fields
Enterprise users can add custom fields to features and experiments. For example, these custom fields can be used to require links to Jira tickets, or to capture additional information that is important to your process or organization. Custom fields can be added from the Settings → Custom Fields page. Custom fields can be set to required or optional, and scoped to specific projects. Currently, custom fields has support for URL, text, textarea (larger text), markdown, number, enum, multiselect, date, and boolean types.
Custom Markdown
Enterprise users can inject custom markdown content into key pages of the GrowthBook app. This feature allows you to provide organization-specific guidance on processes for setting up experiments and features. Additionally, we've made certain Handlebars variables available on each page. This enables you to use Handlebars templates to dynamically customize your messaging based on context.
For example, writing
{{#if tags}}
Guidance for experiments with tags...
{{/if}}
in markdown for the Experiment page becomes Guidance for experiments with tags... when the experiment has at least one tag.
| Page | Variables |
|---|---|
| Experiments List | user orgName |
| Experiment | user orgName experiment experimentStatus tags |
| Features List | user orgName |
| Feature | user orgName featureKey featureType tags |
| Metrics List | user orgName |
| Metric | user orgName metricName metricType metricDatasource tags |
To view and edit custom markdown, go to Settings → General → Custom Markdown → View Custom Markdown Settings.
Searching
GrowthBook has a powerful search feature that allows you to quickly find the feature, experiment, or metrics. By default, text searches with this search input will search based on the name, description, and other meta information. You can also search using syntax search to search for specific fields.
Syntax Search
Syntax search allows you to search for specific fields in GrowthBook. The syntax search allows for exact
matching, starts with, greater, less, and contains. You can also negate any of the operators using !.
Syntax searches are constructed in the format of [field]:[operator][value]. You can also combine multiple
fields using the same syntax. For example, name:~pricing status:running will search for all running experiments
with the name containing the string "pricing".
| Syntax operator | Description |
|---|---|
| : | exact match |
| := | exact match |
| :~ | contains |
| :^ | starts with |
| :> | greater than |
| :< | less than |
| :! | negated (exclude matches) |
| :!= | negated (exclude matches) |
| :!~ | does not contain |
| :!^ | does not starts with |
| :!> | not greater than |
| :!< | not less than |
You can also add quotes to search for fields that contain spaces. For example, name:"New Feature" will search for
the name field that contains the text “New Feature”.
Experiments Syntax Fields
| Syntax field | Description | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| name | The experiment name (eg: name:~pricing) | ||||||||||||||||||
| key or id | The experiment's tracking key (eg: key:^banner) | ||||||||||||||||||
| status | Experiment status, can be one of "stopped", "running", "draft", "archived" (eg: status:running) | ||||||||||||||||||
| owner | The creator of the experiment (eg: owner:pat) | ||||||||||||||||||
| tag | Experiments tagged with this tag | ||||||||||||||||||
| project | The experiment's project | ||||||||||||||||||
| feature | The experiment is linked to the specified feature | ||||||||||||||||||
| datasource | Experiments that use a specific data source (eg: datasource:bigquery) | ||||||||||||||||||
| metric | Experiments that contain the metric specified (eg: metric:~revenue) | ||||||||||||||||||
| result | The experiment result (won, inconclusive, lost, unfinished) | ||||||||||||||||||
| variation | The experiment contains a variant with the name specified | ||||||||||||||||||
| variations | Search for the number of variants | ||||||||||||||||||
| created | The experiment's creation date, in UTC. The date entered is parsed so supports most formats | ||||||||||||||||||
| updated | The date the experiment was updated, in UTC. The date entered is parsed so supports most formats | ||||||||||||||||||
| variations | Search for the number of variants | ||||||||||||||||||
| savedgroup | Show any experiments that are using saved groups (ID lists) in the experiment targeting conditions | ||||||||||||||||||
| is | Supports searching on the experiment status, results, and other current states. Supported fields
| ||||||||||||||||||
| has | Supports searching on the experiment states. Supported fields
|
Examples
name:~pricing status:running
Show all running experiments with the name containing the string "pricing"
tag:checkout result:won updated:>2024-06-05
Show all experiments tagged with "checkout" that have been marked as won and were updated after June 5th, 2024
is:archived has:visualChange variations:>2
Show all archived experiments that have a visual change and have more than 2 variations in the experiment
owner:patty has:!hypothesis
Show all experiments owned by Patty that do not have a hypothesis
created:<"dec 22nd, 2023" has:redirect metrics:~revenue
Show all experiments that have a redirect and were created before December 22nd, 2023 and contain a metric name containing "revenue"
Features Syntax Fields
| Syntax field | Description | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| key | The feature's key (name) | ||||||||||||||||
| owner | The creator of the feature (eg: owner:abby) | ||||||||||||||||
| rules | Matches based on the number of rules (eg: rules:>2) | ||||||||||||||||
| tag | Features tagged with this tag | ||||||||||||||||
| project | The feature's project | ||||||||||||||||
| version or revision | The feature's revision number | ||||||||||||||||
| experiment | The feature is linked to the specified experiment | ||||||||||||||||
| created | The feature's creation date, in UTC. Date entered is parsed so supports most formats. (eg: created:>"2024-06-05" or created:<"dec 22nd, 2023") | ||||||||||||||||
| updated | The date the feature was updated, in UTC. Date entered is parsed so supports most formats | ||||||||||||||||
| savedgroup | Show features that have rules referencing a saved group or ID list | ||||||||||||||||
| on | Shows features that are on for a specific environment (on:production) | ||||||||||||||||
| off | Shows features that are off for a specific environment (off:dev) | ||||||||||||||||
| is | supports searching on the feature status, results, and other current states. Supported fields
| ||||||||||||||||
| has | supports searching on the feature states. Supported fields
|
Examples
key:~pricing on:production
Show all features with the key containing the string "pricing" that are on in the production environment
tag:checkout stale:true
Show all features tagged with "checkout" that are stale
is:archived has:prerequisites
Show all archived features that have prerequisites
owner:abby has:draft rules:0
Show all features owned by Abby that have a draft and have no rules
updated:>"2024-06-05" has:experiment
Show all features that have experiment rules and were updated after June 5th, 2024
Metrics Syntax Fields
| Syntax field | Description | ||||||
|---|---|---|---|---|---|---|---|
| name | The metric name (eg: name:~revenue) | ||||||
| id | The metric's id (eg: id:met_abc123) | ||||||
| type | The type of metric. Either proportion, mean, ratio, or quantile. We also support some legacy naming if you prefer to search with that: binomial, count, revenue, and duration. | ||||||
| owner | The creator of the metric (eg: owner:pat) | ||||||
| tag | Search by metric tag tag | ||||||
| project | The metric's project | ||||||
| datasource | Metrics that use a specific data source (eg: datasource:bigquery) | ||||||
| created | The metric's creation date, in UTC. The date entered is parsed so supports most formats | ||||||
| updated | The date the metric was last updated, in UTC. The date entered is parsed so supports most formats | ||||||
| is | supports searching on the metric properties. Supported fields
| ||||||
| has | supports searching on various metric properties. Supported fields
|
Examples
type:ratio name:~session
All ratio metrics where the name contains "session"
tag:checkout is:fact
All fact metrics with the tag "checkout"
updated:>"2024-06-05" owner:jeremy
Show all metrics owned by "jeremy" that were updated after June 5th, 2024