Sticky Bucketing
This article serves two purposes:
- High level overview of GrowthBook's Sticky Bucketing feature
- Technical details on how to implement Sticky Bucketing in your codebase
Sticky bucketing ensures users continue to see the same variation when you make changes to a running experiment. GrowthBook's flavor of sticky bucketing has a few additional features:(1) Bucketing based on either a primary hash attribute (i.e. user id) or a secondary attribute (i.e. anonymous id) and (2) the ability to version-control and purge your users' assigned buckets.
Motivation
So why would you want to use Sticky Bucketing? Let's look at a few examples:
-
You are managing an experiment rollout and need to slow down enrollment. You decrease the percentage of traffic exposed to the experiment from 50% to 10% but you do not want to alter the experience for users who were already exposed to the experiment. Sticky bucketing allows you to apply the rollout percentage to new users while keeping the old users in their original buckets.
-
You discovered a bug in your experiment the day after launching. You fix the bug and want to re-start the experiment, but don't want to include any "tainted" users who saw the buggy version since their negative experience might impact the results.
-
Your have a cross-platform app and want to ensure a consistent experience as users log in and move between devices.
Sticky Bucketing is a GrowthBook Pro and Enterprise feature.
Setting up Sticky Bucketing
To use Sticky Bucketing for your experiments, there are a few steps that you need to complete.
1. Ensure you are using a compatible SDK version
Update your codebase to use a compatible SDK. Sticky Bucketing is currently supported in the following SDK versions:
- Javascript:
0.32.0 - React:
0.22.0
2. Pass a Sticky Bucketing Service into your SDK Implementation
You may use one of our built-in Sticky Bucketing Services or implement your own. We provide common drivers for browser-generated cookies, backend-generated cookies, browser LocalStorage, and Redis stores.
For more information about setting up Sticky Bucketing at the SDK level, see the appropriate SDK documentation. For instance, see the Javascript SDK - Sticky Bucketing documentation for more information about setting up Sticky Bucketing in the Javascript SDK.
3. Update your SDK Connections in the GrowthBook app
Within the GrowthBook app, ensure that your SDK Connections are configured correctly. You can do this by going to the SDK Connections page, clicking into a connection, and clicking the Edit button in the top right.
Make sure the connection (1) only has a single language selected and (2) has the correct SDK version specified.
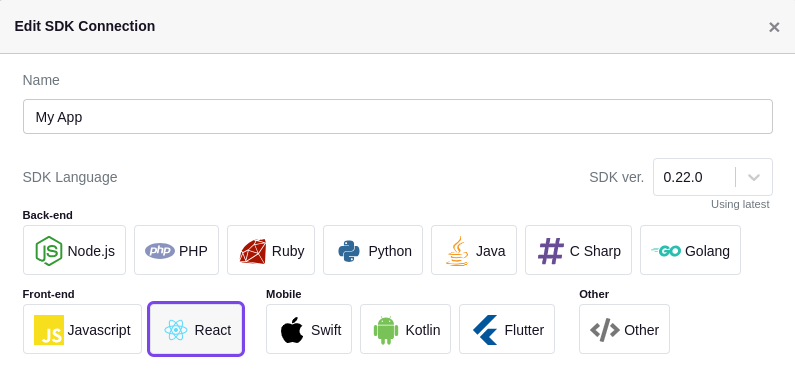
In the above example, React is selected and the version is set to the latest 0.22.0, which supports sticky bucketing.
If you are using GrowthBook with multiple languages, create a separate SDK Connection for each language.
4. Enable Sticky Bucketing for your organization
In the GrowthBook app, go to Settings → General → Experiment Settings and enable the Sticky Bucketing toggle. This will add new options specific to Sticky Bucketing whenever you make changes to a running experiment. To read more about these options, see Experiments (setup).
Once Sticky Bucketing is enabled, there is an additional toggle for enabling a Fallback Attribute. See below for more information on this feature.
Fallback Attribute
Users are assigned an experiment variation based on a Hash Attribute, for example a logged-in userId. With Sticky Bucketing, you also have the option of specifying a Fallback Attribute for an experiment, for example an anonymous cookieId. This fallback will be used if the primary hash attribute is missing or empty.
Fallback Attribute Example
Imagine your users tend to sign in on multiple devices. Let's say you want to test changes to the main navigation header of your app, something that is visible to both logged-in and anonymous visitors.
If you were to only use userId to assign variations, signing in could become a jarring experience - users might flip from seeing the control (since their user id is empty) to seeing the variation (once they log in). On the plus side, if users open your app on multiple devices (when logged in), they will always see a consistent experience.
If instead, you were to only use the anonymous cookieId to assign variations, it solves the issue where the UI flips during sign in (since the anonymous id stays the same before and after), but now switching devices could become a jarring experience - the same user might get assigned different variations on different devices, since each device would have its own separate anonymous id.
Fallback attributes, when implemented properly with sticky bucketing, lets you have the best of both worlds (with some caveats). Your primary hashing attribute would be the logged-in userId and your fallback attribute would be the anonymous cookieId.
The very first variation a user is assigned to will "stick" to them and follow them across devices. So if a visitor lands on your website, gets assigned variation B (from their fallback attribute), and then logs in, they will continue seeing variation B, even though they now have a userId attribute. If that same user then logs into your app on a new device, they again will continue seeing variation B.
There are 2 caveats with fallback attributes:
- There are still some scenarios where users will get inconsistent experiences. For example, if they are logged out on two devices, there's no way for us to know they are the same person.
- It opens you up to potential bias in your experiment results (see more below).
Bias Risk
To understand the risk of bias, lets focus on a user switching devices. During analysis, we will have to use the anonymous cookieId as the experimental unit to make sure we capture everyone in the experiment, even those who never logged in. When a user logs in on two devices, they will be seen as two separate "users" in the analysis since each device has its own cookie id. Because of the fallback attribute and sticky bucketing, however, they will both get assigned the same variation. This breaks one of the statistical assumptions of A/B testing - that each user is randomly assigned a variation. Let's see how this might play out to cause bias in your results.
Imagine your variation causes people to use multiple devices more often than your control does. 200 people land on your website and get split into control and variation - 100 in each. In the control, 20 of them also log in on their phone, but in the variation 60 of them log in on their phone. In your analysis, you have 280 total anonymous ids and you expect them to be split evenly - 140 each. In reality, the control would have 120 ids while the variation has 160. A difference this extreme is easy to spot in the results (GrowthBook runs Sample Ratio Mismatch tests automatically to catch exactly this type of bug), however there are many similar, but more subtle, issues that may fly under the radar.
Bottom line: with Fallback Attributes, you can get a more consistent within-session and cross-device user experience at the expense of statistical rigor. With GrowthBook, we let you decide this trade-off for yourself on a per-experiment basis.
Example Sticky Bucket Implementations
Front-end only
Suppose your website integrates GrowthBook on the front end only. You would like to implement Sticky Bucketing to protect against variation hopping should targeting or rollout rules change in the future.
In our JavaScript and React SDKs, we provide 2 different Sticky Bucket Services that make sense in this scenario: LocalStorageStickyBucketService and BrowserCookieStickyBucketService. You can instantiate either of these services and plug them into the GrowthBook SDK.
Front-end and Back-end (Node.js)
Let's expand the "front-end only" example above so that our back-end controllers also integrate with GrowthBook and can reference the same experiments. In this scenario, we would like both the front-end and back-end to perform bucketing and persist a sticky bucket that reliably crosses the front-end / back-end divide.
On the front end, you will want to use the BrowserCookieStickyBucketService because cookies are easily transportable to and from the back end. Then, assuming we are using an Express (NodeJS) server, we would use the ExpressCookieStickyBucketService on the back end. Importantly, if customizing the cookie name, you must ensure that the same name prefix is chosen for both the front-end and back-end cookies.
Back-end only
Suppose that in a server-side context we are interested in persisting a user's bucket both across multiple requests and across other back-end (micro)services that may not have direct access to the incoming user request nor their cookies.
We could use a Redis instance inside our network and read/write to that for sticky bucket storage. In a NodeJS context, we could use the RedisStickyBucketService and pass in an ioredis client.
Hybrid and custom implementations
You may wish to employ multiple strategies at once (front-end, back-end, Redis) or write your own sticky bucket connector for a SQL server or DynamoDB cluster. You could write your own custom sticky bucket connector by implementing the StickyBucketService interface. Within your connector, you could do things like:
- Connect to SQL server for sticky bucket reads/writes
- GET/POST/RPC to a custom bucketing microservice
- Wrap both the
ExpressCookieStickyBucketServiceandRedisStickyBucketServicewithin your custom service's getter and setter methods - Trigger side effects on bucket reads/writes